How Rapid Works
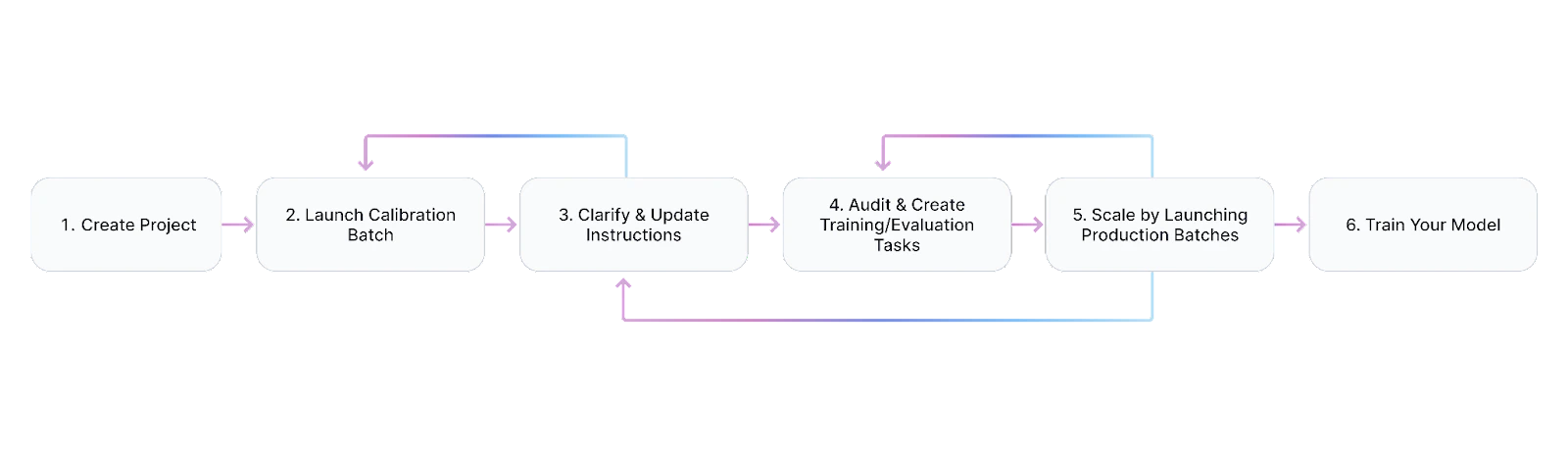
Scale Rapid is our self-serve data annotation platform and is the fastest path to production-quality labels, with no minimums. Our goal is to reduce the time to quality for any labeling project from months to hours. When you first create a project, you will upload your data. Our supported data formats include images, videos, text, documents, and audio. You will then be able to select from a list of available use cases for your uploaded data format. Each use case comes with a set of available labels that you can use to create your taxonomy and a set of available pipelines (i.e. sequence of stages for a task to go through before being delivered back to you). Each project will have one selected pipeline. Every task within a project will go through the same pipeline. In your project, you will write instructions explaining how to label your task. This step is very important to help you achieve quality on your project. After creating your project, building your taxonomy, and writing instructions, you will launch a calibration batch for labeling. Or, you can launch a self-label batch first to test your taxonomy setup or experience labeling on the Rapid platform. After launching a calibration batch, you will receive feedback from Scale labelers on your instructions and see your first set of task responses. We recommend analyzing the discrepancies between your instructions and task responses and improving upon your instructions accordingly. While auditing, you will be able to use those tasks to create examples embedded in your instructions and quality tasks to further improve your overall project setup. When you are satisfied with your instructions and quality task setup, you can then scale to larger volumes and launch production batches at a regular cadence. We recommend periodically checking into your project and auditing some tasks to make sure that your labels are at a steady-state quality level.