Professional Reasoning Benchmark - Finance
Overview
Professional Reasoning Benchmark (PRBench) is the first benchmark to evaluate LLMs on high-stakes professional reasoning in Finance and Law. While academic benchmarks like MMLU and GPQA have become standard metrics for tracking AI progress, they fail to test for real-world professional utility where domain knowledge, nuanced judgment, and contextual understanding are critical.
What sets PRBench apart is its foundation in reality: the benchmark comprises real questions from 182 domain experts, many carrying direct economic consequences rather than abstract academic exercises. These questions represent the kinds of decisions that affect financial outcomes, legal liability, and business operations every day in professional settings.
Read the paper here: https://scale.com/research/prbench
Check out some of the data here: https://prbench-explorer.vercel.app/
Dataset Design
PRBench was co-designed with 182 professionals who bring deep domain expertise—JDs for Law and CFAs, Masters degrees, or 6+ years of professional experience for Finance. Each task features an expert-curated rubric containing 10-30 weighted criteria, scored from -10 to +10, designed to penalize harmful or incorrect advice while rewarding high-quality, safe responses.
The benchmark emphasizes realistic context, with approximately 30% of the 1,100 tasks structured as multi-turn conversations that build context progressively, mimicking real-world professional interactions. The global scope is unprecedented, with tasks covering 114 countries and 47 distinct US jurisdictions.
The benchmark offers two evaluation sets:
Full Dataset: All 1,100 questions (600 Finance, 500 Legal)
Hard Subset: The most challenging 550 questions (300 Finance, 250 Legal) specifically designed to test frontier models
Methodology and Core Metrics
PRBench uses an LLM judge (o4 Mini) to evaluate model responses against each rubric criterion, producing a final weighted score that is clipped from 0-1 for standardization.
The benchmark's reliability has been validated through two rigorous processes:
Rubric Validation: An independent set of experts validated the rubric criteria, achieving 93.9% agreement on their clarity and validity
Judge Validation (IRA): The o4 Mini judge demonstrates 80.2% agreement with human experts, on par with the 79.6% agreement between two human experts
Performance is analyzed across 11 rubric categories, including Legal/Financial Accuracy, Process Transparency & Auditability, and Risk & Ethical Disclosure, providing granular insights into model capabilities.
Data Summary
Finance | Legal | |
Total Samples | 600 | 500 |
Hard Subset | 300 | 250 |
User Expertise | 74% Expert / 26% Non-Expert | 53% Expert / 47% Non-Expert |
Median Criteria per Task | 16 | 17 |
Total Criteria | 10,264 | 9,092 |
Key Results and Insights
Current Best Performance (Hard Subset): Even top models fail to breach a 0.40 score, revealing substantial room for improvement in professional reasoning:
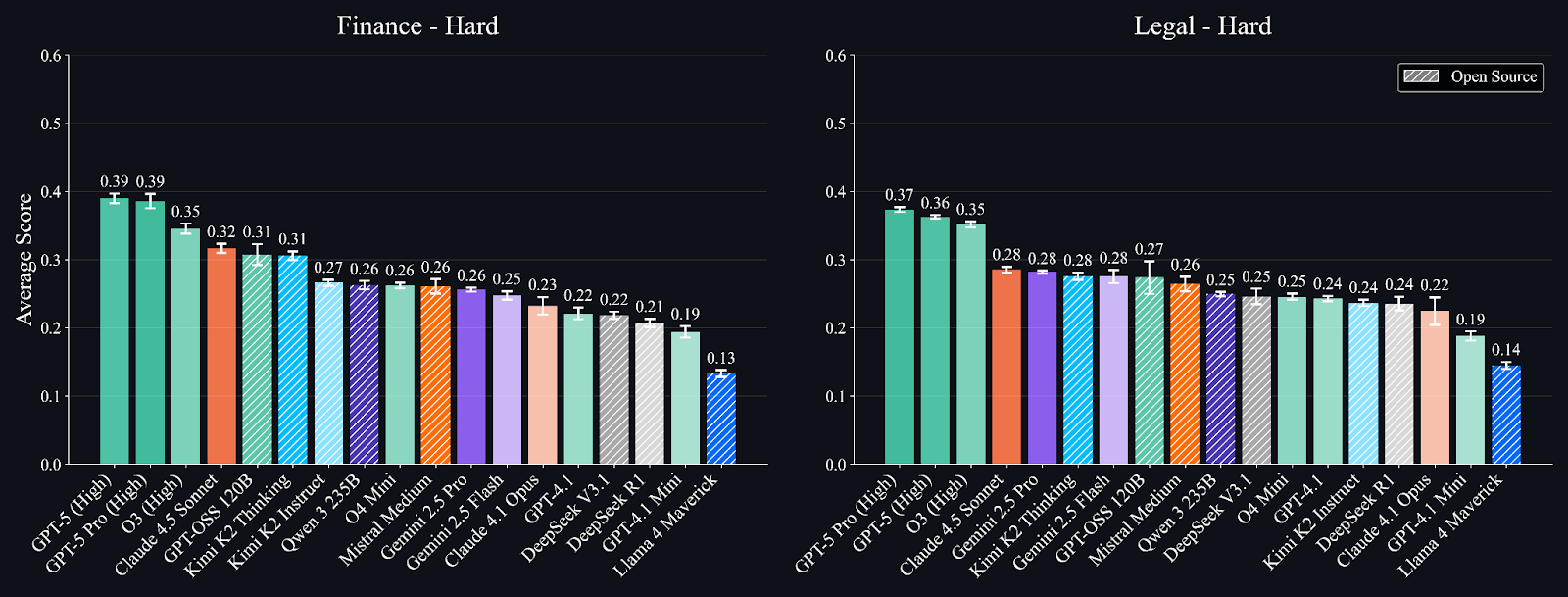
Finance (Hard): 1. GPT-5 Pro (0.39), 2. GPT-5 (0.39), 3. o3 (High) (0.35)
Legal (Hard): 1. GPT-5 Pro (0.37), 2. GPT-5 (0.36), 3. o3 (High) (0.35)
Systematic Weaknesses: Across all models tested, consistent struggles emerge with Process Transparency & Auditability, Handling Uncertainty, and domain-specific diligence. These gaps are particularly concerning for professional applications where explainability and thoroughness are essential.
Key Finding: Models frequently reach correct conclusions through incomplete or opaque reasoning processes, significantly reducing their practical reliability in professional settings where the reasoning path matters as much as the answer.
Efficiency vs. Performance: Conciseness emerges as a key differentiator among similarly performing models. For instance, in Finance tasks, Kimi K2 Thinking achieves comparable performance to Claude 4.5 Sonnet but with substantially shorter, more efficient responses.
Tools Impact: Enabling web search improves performance for models, but can actually hurt others that tend to over-rely on external sources rather than applying professional judgment.
Performance Comparison
claude-opus-4-6 (Non-Thinking)
53.28±0.18
gpt-5
51.32±0.17
gpt-5-pro
51.06±0.59
o3-pro
49.08±0.79
gpt-5.1-thinking
48.01±0.09
o3
47.69±0.45
kimi-k2.5
46.51±0.34
gpt-5.2-pro-2025-12-11
46.34±0.73
claude-opus-4-5-20251101-thinking
46.16±0.27
gpt-oss-120b
43.80±1.96
claude-sonnet-4-5-20250929
43.79±0.40
kimi-k2-thinking
43.41±0.23
mistral-medium-latest
39.35±0.75
o4-mini
39.22±0.51
gemini-3-pro-preview
39.18±0.51
qwen.qwen3-235b-a22b-2507-v1:0
39.14±0.38
gemini-2.5-pro
38.92±0.48
gemini-2.5-flash
38.41±0.62
kimi-k2-instruct
38.34±0.42
claude-opus-4-1-20250805
35.15±1.27
deepseek-v3p1
35.09±0.15
gpt-4.1
34.32±0.26
deepseek-r1-0528
32.67±0.64
gpt-4.1-mini
30.45±0.42
llama4-maverick-instruct-basic
22.36±0.42
Rank (UB): 1 + the number of models whose lower CI bound exceeds this model’s upper CI bound.
-
CE: Calibration Error