SciPredict
LLMs often struggle with a core scientific capability: forecasting experimental outcomes. Doing so requires integrating experimental design, background knowledge, and causal reasoning to anticipate real-world results. SciPredict evaluates this capability directly, testing whether frontier models can predict the outcomes of real experiments in physics, biology, and chemistry rather than rely on theoretical recall or simulated tasks.
For each experiment, experts distill the experimental setup and separate it from the reported outcome. Relevant background knowledge is explicitly annotated, enabling evaluation with and without external context. Models also self-report confidence, perceived difficulty, and feasibility (whether an outcome can be predicted without running the physical experiment) enabling analysis of calibration alongside predictive accuracy. All questions are drawn from recent scientific literature, ensuring models must reason about new science rather than recite training data.
Read the full paper here: https://scale.com/research/scipredict
Dataset Design
SciPredict is constructed to reflect the structure and information constraints of real empirical science. Each evaluation item is derived from a recently published experimental study and is designed to test whether a model can reason from experimental setup to outcome, rather than rely on factual recall.
Key dataset properties:
Post-cutoff novelty: All questions are sourced from scientific papers first appearing online after March 31, 2025, reducing the likelihood of training data contamination.
Domain coverage: The benchmark focuses on experimentally rich areas of the physical sciences, including physics, biology, and chemistry, where empirical measurements and multi-step workflows are central to advancing knowledge.
Expert curation: Domain experts distill each paper into a structured experimental description, explicitly extracting the system, conditions, procedures, and interventions while separating the setup from the reported outcome.
Annotated background knowledge: For each experiment, experts document the specific background information helpful to deduce the result.
Context toggling: Background knowledge can be provided or withheld at evaluation time, enabling controlled comparison of model performance with and without external context.
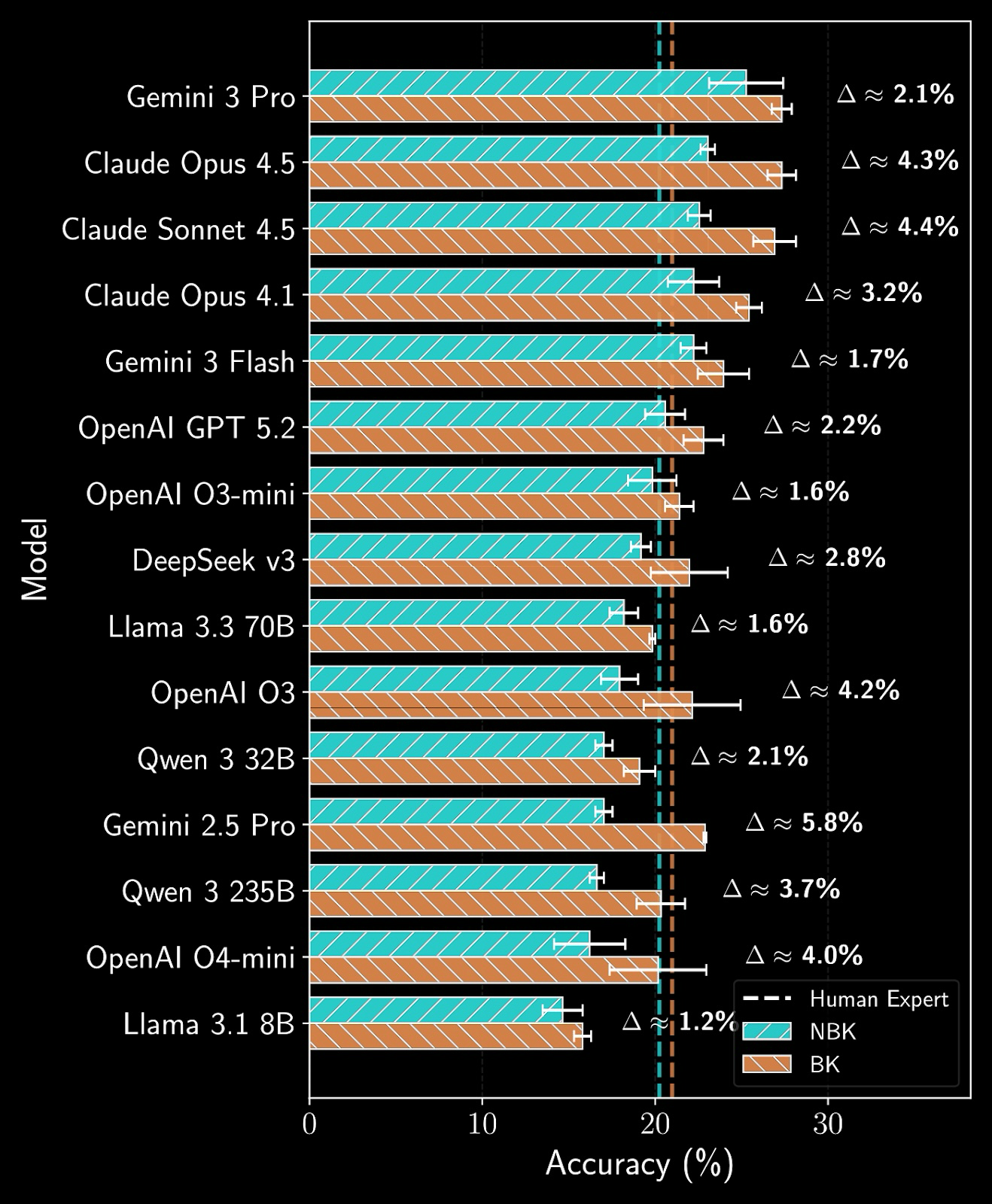
This design isolates empirical outcome prediction as a capability while supporting analysis of how models rely on prior knowledge, provided context, and reasoning under realistic scientific conditions. The figure below illustrates how access to expert-annotated background knowledge affects predictive accuracy. Note: NBK: no background knowledge, BK: with background knowledge.
Methodology
SciPredict evaluates models in a zero-shot setting to measure predictive performance under standardized conditions. For each question, models are provided with a fixed task instruction and the experimental details . Depending on the evaluation condition, models may also receive expert-annotated background knowledge.
Evaluation Modes
To capture a spectrum of scientific reasoning—from qualitative decision-making to exact quantitative calculation—we evaluate models across three formats:
Multiple-Choice (MCQ): Models select the correct outcome(s) from 3–4 plausible options, testing their ability to identify correct mechanisms under constrained conditions.
Free-Form (FF): Models generate an open-ended prediction and explanation. Accuracy is determined by a fixed-prompt judge model evaluating the response to a set of expert written rubrics.Numerical Prediction (NUM): Models predict quantitative values. A prediction is considered correct if it falls within an expert-defined acceptable interval [L,U].
Core Metrics
We report four primary metrics:
Accuracy: Accuracy is defined per format; MCQ and free-form responses are evaluated as correct or incorrect, while numerical predictions use interval-based matching. Calculated separately for each evaluation format.
Self-Reported Confidence: A rating from 1 (“very low confidence”) to 5 (“very high confidence”), interpreted as the model’s subjective assessment that its prediction is correct.
Self-Assessed Difficulty: A rating from 1 (“very easy”) to 5 (“very hard”) indicating perceived task difficulty.
Feasibility Judgment: A rating from 1 (“not feasible to predict without experimentation”) to 5 (“highly feasible to predict without experimentation”) indicating whether the outcome can be deduced from the provided information alone.
Data Summary
Domains: Questions span physics, biology, and chemistry, covering a range of experimental systems, interventions, and measurement types.
Question formats: The dataset includes a mix of multiple-choice (MCQ), free-form (FF), and numerical prediction (NUM) questions.
Evaluation conditions: Models are evaluated both with and without expert-annotated background knowledge.
Total scale: The benchmark consists of 405 expert-curated experimental prediction tasks sourced from publications after March 31, 2025.
How to Read the Leaderboard
Raw accuracy alone does not fully capture model behavior on empirical outcome prediction. SciPredict reports additional signals (context sensitivity, confidence, and perceived difficulty) to support more nuanced interpretation of leaderboard scores.
Background knowledge effects: Providing expert-annotated background knowledge often leads to substantial improvements in accuracy, indicating that many models struggle to reconstruct necessary scientific context from experimental descriptions alone; by contrast, self-generated background knowledge often degrades performance.
Confidence vs. correctness: While background knowledge improves predictive accuracy, model confidence frequently remains unchanged. This suggests that gains in performance do not reliably translate into improved self-assessment.
Difficulty calibration: Self-assigned difficulty is not consistently aligned with empirical accuracy. Models sometimes perform better on questions they label as difficult than on those they consider easy, highlighting limitations in difficulty awareness.
Feasibility calibration: Model judgments about whether an outcome can be predicted without experimentation are not consistently aligned with empirical accuracy, limiting their usefulness as a reliability signal.
Domain sensitivity: Performance varies by scientific domain. Chemistry is typically the most challenging subset, with lower accuracy on average than Biology and Physics.
Format dependence: Models are consistently more reliable on multiple-choice questions than on matched free-form versions of the same items, reflecting the strong benefit of being provided with candidate answers.
Taken together, the leaderboard is best interpreted as a multi-dimensional evaluation: accuracy reflects outcome prediction performance, while confidence, difficulty, and feasibility provide insight into how reliably models assess their own reasoning under realistic scientific uncertainty.
Performance Comparison
gemini-3-pro-preview
25.27±1.92
claude-opus-4-5-20251101
23.05±0.51
claude-opus-4-1-20250805
22.22±1.48
claude-sonnet-4-5-20250929
22.55±0.75
gemini-3-flash
22.22±1.08
gpt-5.2-2025-12-11
20.58±1.03
o3-mini-2025-01-31
19.84±1.49
DeepSeek-V3
19.18±0.79
Llama-3.3-70b
18.19±0.79
o3-2025-04-03
17.94±1.27
gemini-2.5-pro
17.04±0.65
Qwen3-32B
17.04±0.49
o4-mini-2025-04-03
16.21±2.10
Qwen3-235B
16.63±0.38
Llama-3.1-8B
14.65±1.03