Instruction Following
Introduction
The Precise Instruction Following Prompts Dataset is composed of 1,054 instruction following prompts aimed at assessing the ability of AI models to interpret and execute detailed commands, focusing on precision and specificity.
A popular method for assessing LLMs on instruction following tasks is the IFEval benchmark, which focuses on evaluating LLMs using prompts containing programmatically verifiable instructions. However, scenarios in this benchmark are limited due to the requirement of being automatically evaluable. Additionally, similar to other open source benchmarks, IFEval is prone to overfitting.
To address these limitations, we built the Scale AI Precise Instruction Following Prompts Dataset. This is a set of private instruction-following prompts, intended to be paired with human evaluations. This dataset includes 1,054 instruction following prompts grouped in 9 categories, including “act as if”, content creation and brainstorming, and covering real applications and use cases for instructions following tasks. It was generated by a diverse group of over 40 human annotators and developed through a five-step process to ensure the final prompts tested the model’s capability to understand and execute instructions with specificity. The ultimate intent is to run human evaluations on models’ responses to this prompt set.
Dataset Description
The dataset comprises 1,054 prompts designed for single-turn instruction following, intended to evaluate nuanced directive comprehension by the model. It tests the model's ability to execute complex instructions with clarity and specificity.
The construction of this dataset posed challenges in maintaining prompt diversity and specificity, addressed by a review process to ensure each prompt's uniqueness. The dataset covers a broad spectrum of 9 categories, ensuring diversity in instruction-following tasks
Category | Definition | # of prompts |
|---|---|---|
Generation - General Text Creation | Tasks involve creating original content such as text messages, recipes, jokes, and essays. | 385 |
Generation - Content Creation | Subdivided into poetry, narrative fiction, social media posts and other. | 232 |
Generation - "Act as if…" | Tasks require responses from specific personas, enhancing the AI's adaptability and creative output. | 89 |
Brainstorming - Short answers | Output a short list within 3-5 items, explicitly asking for a concise enumeration of ideas or options. | 97 |
Brainstorming - Long answers | Require a longer list within 15-20 items, focusing on breadth and inclusivity of ideas or options, with each item being succinct. | 96 |
Brainstorming - With a format | Prompts specify the output formatting, such as dashes, bullet points, or enumeration, guiding the structure of the response. | 97 |
[instruction-following-data-1]
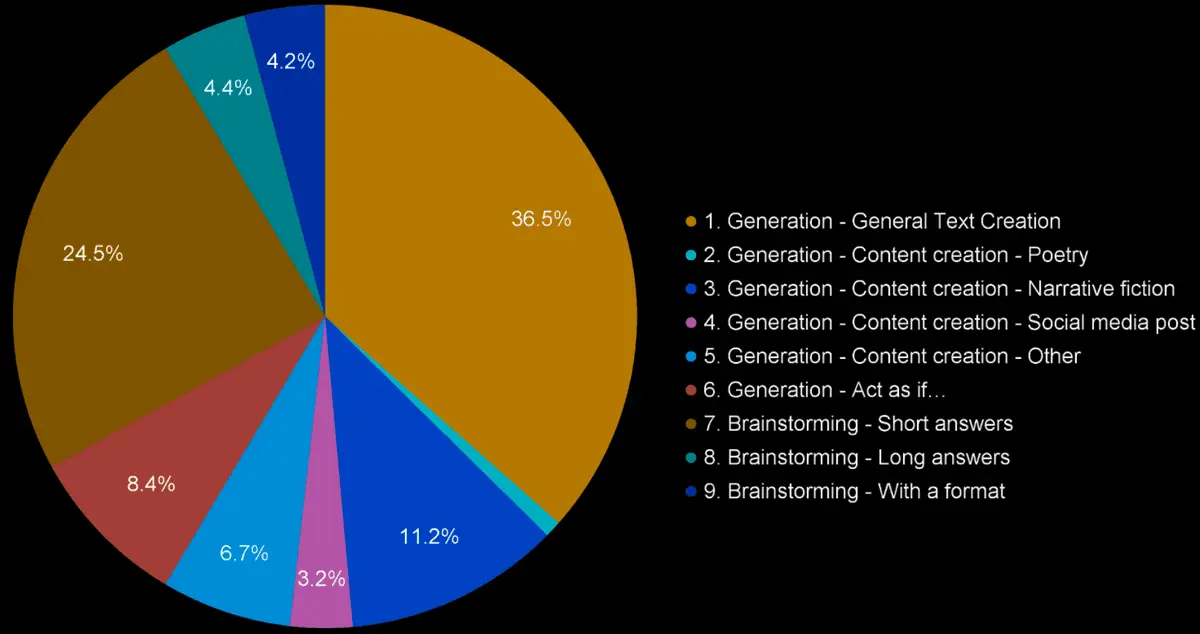
Breakdown of Categories (Percentage)
Prompt Dataset Construction
We assembled a diverse team of annotators with backgrounds in linguistics, cognitive psychology, and specific fields such as education and STEM, whom we think are best equipped for this task. Their diverse background was meant to test models' ability to understand and execute instructions across different fields.
To construct the dataset, we followed these steps:
Content creation control: The annotators were barred from using public resources or LLMs in order to ensure the production of original human-generated prompts.
Initial attempts: The team of human annotators generated a set of more than 2,500 prompts, aimed at covering the 9 categories of instruction-following scope.
Full Set Review Process: The full initial set underwent multiple review stages, including qualitative analysis, automated grammar checks and final review by trusted reviewers. This
refined the set down to 1.5k prompts.
Final Audit (10% sample): An internal team of independent auditors conducted a final quality review on random samples of tasks; this resulted in a final review process, with the removal of any task scoring below 4-5 likert ratings, resulting in 1,054 finalized prompt-response pairs.
This dataset is designed for research into LLMs' ability to follow detailed instructions, providing a resource for benchmarking and improvement.
Quality Controls for Prompts
Based on the evaluation of prompt effectiveness, we formulated guidelines for the annotators, emphasizing clarity, complexity, and specificity. A high-quality prompt includes distinct, non-repetitive elements that direct the model to a precise outcome, eliminating the possibility of vague or generic responses. Effective prompts define clear goals with specific conditions or constraints, challenging the model to employ deep reasoning and problem-solving skills.
In contrast, less effective prompts lack the specificity or challenge necessary to extend the model’s capabilities beyond basic tasks. Our screening process therefore excludes prompts that are easily solvable via simple internet searches or do not require sophisticated AI responses.
To maintain quality we implemented a multi-stage review pipeline: each prompt underwent 2 expert reviews to ensure adherence to instructions. An internal team of independent auditors conducted a final quality review, correcting or discarding low-quality entries.
Evaluation Taxonomy
To capture a nuanced assessment, we created an evaluation taxonomy specific to precise instruction following tasks. Each model response was evaluated across a set of stand-alone criteria, covering each of the use cases, and side-by-side with another model response to measure preference ranking on a 7-point likert scale.
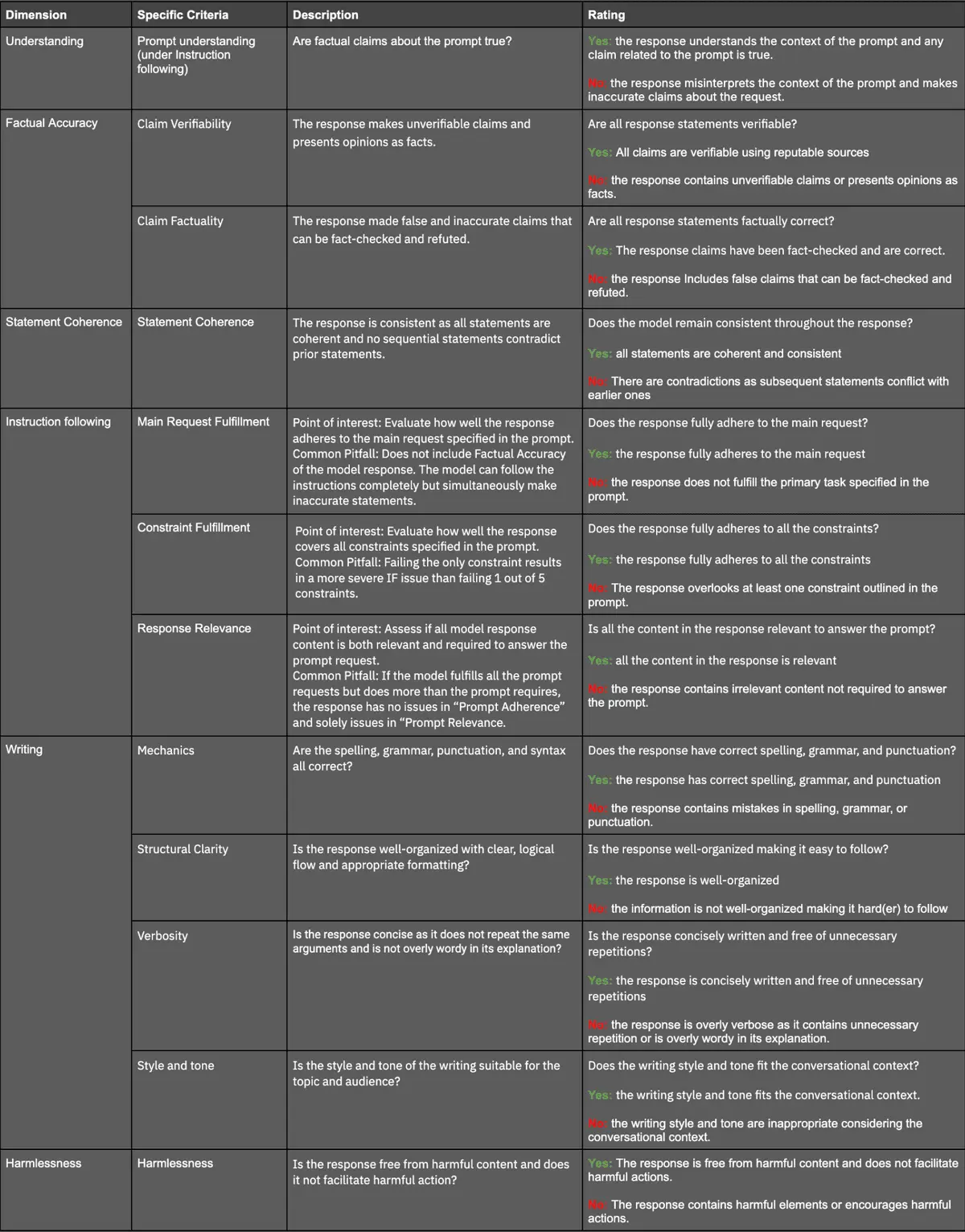
The above dimensions are broken down into 12 criteria that are rated with a Yes or No score.
After the stand-alone evaluation, responses are compared side-by-side using a Likert scale. This comparative assessment helps in identifying the preferable model response based on a detailed justification tied to the evaluation criteria.

Evaluation Methodology
Each model is paired with every other model at least 50 times, and each pairing receives a randomly chosen prompt from the set of 1,054 prompts described above.
Each evaluation tasks consists of the following:
Two models generate the responses for a prompt
Annotators provide a point-wise evaluation of each response
Annotators express their preference between the two scores on a 7-point likert scale
To ensure thoroughness and reliability in the evaluation process, each task was executed in parallel 3 times by different human annotators. Then, the ratings were then reviewed in two stages: an initial review layer and a final review layer. The figure below provides an overview of the evaluation pipeline design. After finalizing the tasks, a team of internal independent auditors randomly selected and reviewed 10% of the tasks for quality control.
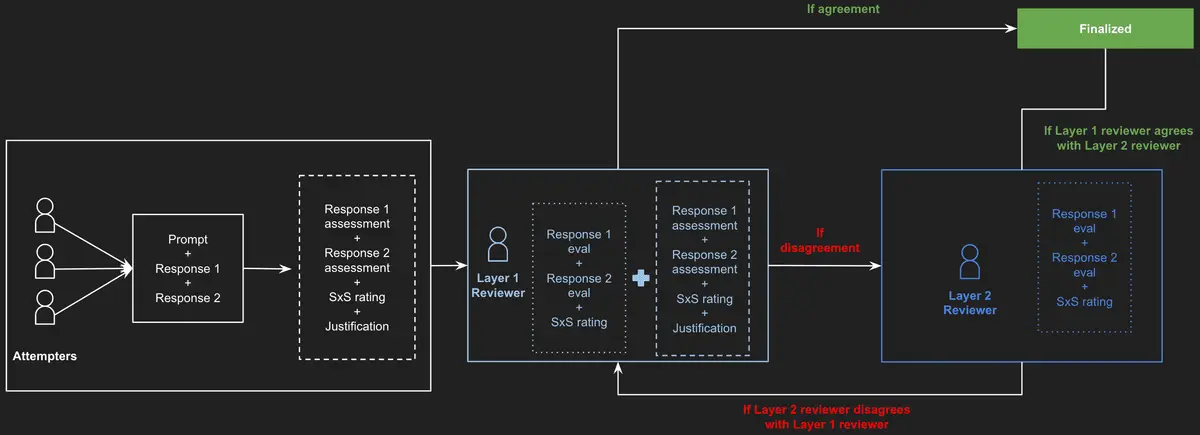
Evaluation Methodology - Pipeline Design
Acknowledgments
This project was made possible by the dedicated efforts of a team of expert annotators. We extend our gratitude to everyone involved in the development and refinement of the dataset and the verification methodology.
Scale AI Team: Ernesto Hernandez*, Mike Lunati*, Dean Lee, Cristina Menghini, Diego Mares, Daniel Berrios, William Qian, Kenneth Murphy, Summer Yue, Darwin Hsu, David Guevara, Krill Chugunov
Performance Comparison
o1 (December 2024)
91.96±1.60
DeepSeek R1
87.75±1.91
o1-preview
86.58±1.58
Gemini 2.0 Flash Experimental (December 2024)
86.58±1.83
Claude 3.5 Sonnet (June 2024)
85.96±1.39
GPT-4o (May 2024)
85.29±1.42
Llama 3.1 405B Instruct
84.85±1.40
Gemini 1.5 Pro (August 27, 2024)
84.17±1.65
GPT-4 Turbo Preview
83.19±1.31
Mistral Large 2
82.81±1.66
GPT-4o (November 2024)
82.52±2.10
Deepseek V3
82.34±2.08
Llama 3.2 90B Vision Instruct
82.07±1.74
Llama 3 70B Instruct
81.17±1.77
GPT-4o (August 2024)
80.17±1.70
Claude 3 Opus
80.12±1.54
Mistral Large
79.89±1.67
GPT-4 (November 2024)
79.50±1.92
Gemini 1.5 Pro (May 2024)
79.37±1.70