Spanish
Introduction
The Scale AI Multilingual Prompts Dataset, composed of 1,000 prompts per language, is tailored to enhance models’ interaction capabilities across multiple languages. This dataset specifically aims to refine chatbots' proficiency in engaging with Spanish users from Spain, Mexico and the rest of Latin America, reflecting complexity of global communication.
Dataset Description
This dataset introduces single-turn prompts across a diversified range of scenarios, aiming to evaluate and improve models’ responses in both general and culturally nuanced conversations.
Category | Definition |
|---|---|
Educational Support | Assist students with academic challenges in an easily understandable manner. |
Entertainment & Recreation | Create engaging experiences with games, trivia, and interactive stories for all ages. |
Coding & Technical Assistance | Provide clear, simple assistance with programming projects. |
Daily Life Assistance | Offer practical advice on everyday tasks like cooking and scheduling. |
Creative Expression | Encourage creativity in arts and writing with inspirational guidance. |
Idea Development & Content Exploration | Help generate ideas and clarify thoughts for innovative minds. |
Information & Learning | Simplify complex topics and support learning new skills across various subjects. |
Personal & Professional Organization | Assist in organizing personal and work lives with actionable advice. |
Shopping & Consumer Research | Provide insights for smart shopping decisions with clear comparisons and recommendations. |
Writing & Communication | Enhance communication skills with tips on various forms of writing. |
Travel Assistance | Simplify travel planning with straightforward advice on destinations and planning. |
Workplace Productivity | Offer straightforward tips to streamline work processes and enhance professionalism. |
Other | Address any additional tasks not specifically listed above, providing flexible support for various needs. |
[spanish-data-1]
Construction Process
Development of this dataset followed a structured approach:
Original Content Requirement: Unique content generation was enforced, prohibiting the use of existing resources or models.
Initial Drafting: Initial creation exceeded 2,500 prompts to encompass a broad linguistic and cultural scope.
Review Stages: The content underwent qualitative and grammatical assessments.
Final Quality Audit: A final evaluation on a select sample refined the dataset to 1,000 prompts.
Experts fluent in various languages with cultural knowledge were chosen to contribute, ensuring the dataset's relevance and authenticity.
Quality was maintained through:
Multi-stage Reviews: Ensuring clarity, complexity, and cultural specificity.
Internal Benchmarking: Monitoring and assessing annotator performance.
Final Audits: Revising or removing prompts that did not meet quality standards.
Evaluation Taxonomy
To capture a nuanced assessment of both general language understanding and of regionalized styles from Spain, México and the rest of Latin América, we created an evaluation taxonomy specific to evaluating this context. Each model response was evaluated across a set of stand-alone criteria, covering a diverse set of use cases, and side-by-side with another model response to measure preference ranking on a 7-point Likert scale.
Main stand-alone criteria and their sub-categories:
Honesty:
Prompt Understanding - Language Consistency: The response uses the same language, unless explicitly requested.
Localization: The model understands the context based on the language, it is appropriate for your locale, by aligning with the culture.
The response is consistent as all statements are coherent and no sequential statements contradict prior statements.
Claim Factuality: The response made false and inaccurate claims that can be fact-checked and refuted.
Claim Verifiability: The response makes unverifiable claims and presents opinions as facts.
Understanding:
Consistency:
Factual Accuracy:
Helpfulness:
Response Relevance:
Point of interest: Assess if all model response content is relevant to address the prompt request.
Common Pitfall: If the model fulfills all the prompt requests but does more than the prompt requires, the response has no issues in “Prompt Adherence” and solely issues in “Prompt Relevance.
Main Request Adherence:
Point of interest: Evaluate how well the response adheres to the main request specified in the prompt.
Common Pitfall: Does not include Factual Accuracy of the model response. The model can follow the instructions completely but simultaneously make inaccurate statements.
Constraint Adherence:
Point of interest: Evaluate if the response covers all constraints specified in the prompt.
Common Pitfall: Incorrectly identify the constraints from other criteria, such as Request Adherence or Writing criteria and penalize this one. Failing the only constraint results in a more severe IF issue than failing 1 out of 5 constraints.
Mechanics: Are the spelling, grammar, punctuation, and syntax all correct?
Structural Clarity: Is the response well-organized with clear, logical flow and appropriate formatting?
Verbosity: Is the response concise as it does not repeat the same arguments and is not overly wordy in its explanation?
Fluency: The response is easy to understand and sounds natural. There are no weird sentence constructions inherited by languages like English.
Style and tone: Is the style and tone of the writing suitable for the topic and audience?
Instruction Following:
Writing:
Harmlessness:
No: The response is free from harmful content and does not facilitate harmful actions.
Yes: The response contains harmful elements or encourages harmful actions.
Is the response free from harmful content and does it not facilitate harmful action?
Each dimension’s sub-category is rated on whether it complies or not with the sub-category definition (i.e. ‘yes’ or ‘no’ binary score).
After the evaluation of stand-alone criteria, responses are compared side-by-side using a Likert scale. This comparative assessment helps in identifying the preferable model response based on a detailed justification tied to the evaluation criteria. We rank the models by the side-by-side elo scores for the leaderboard rankings.
Evaluation Methodology
Each model is randomly paired with other models, and each pairing receives a randomly chosen prompt from the set of 1,000 prompts described above.
Each evaluation tasks consists of the following:
Two models generate the responses for a prompt
Annotators provide a point-wise evaluation of each response
Annotators express their preference between the two scores on a 7-point Likert scale
To ensure thoroughness and reliability in the evaluation process, each task was executed in parallel 3 times by different human annotators. Then, the ratings were then reviewed in two stages: an initial review layer and a final review layer. The figure below provides an overview of the evaluation pipeline design. After finalizing the tasks, a team of internal independent auditors randomly selected and reviewed 10% of the tasks for quality control.
Evaluation Methodology - Pipeline Design
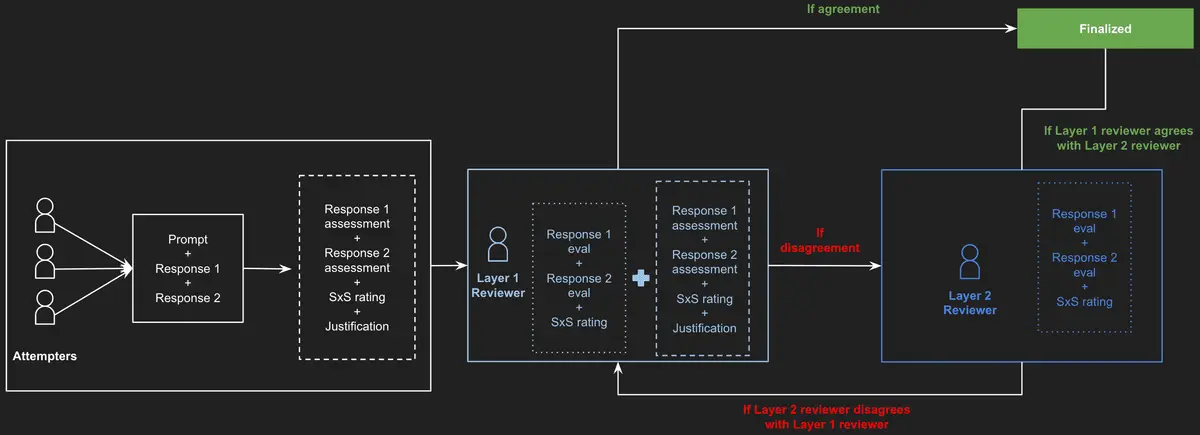
Leaderboard rankings are determined using Rank (Upper Bound), which reflects a model’s statistical position based on confidence intervals. The ranking process follows these steps:
Count the number of models that are statistically significantly better than the target model.
Add 1 to this count to determine the model’s rank.
A model is considered statistically significantly better than another if its lower-bound score (95% confidence interval) is higher than the other model’s upper-bound score.Models receive the same rank when the same number of models are statistically better than each of them. This approach groups models based on statistical significance rather than raw scores, ensuring rankings reflect meaningful performance differences.
Performance Comparison
Gemini 2.0 Pro (December 2024)
1176.00±38.00
o1 (December 2024)
1134.00±36.00
Gemini Pro Flash 2
1119.00±32.00
o1-preview
1111.00±27.00
Gemini 2.0 Flash Thinking (January 2025)
1108.00±34.00
Gemini 1.5 Pro (November 2024)
1105.00±30.00
GPT-4o (May 2024)
1084.00±24.00
o3-mini
1079.00±33.00
Gemini 1.5 Pro (May 2024)
1069.00±26.00
Gemini 1.5 Pro (August 27, 2024)
1067.00±23.00
GPT-4o (August 2024)
1067.00±26.00
GPT-4 (November 2024)
1034.00±31.00
Mistral Large 2
1032.00±24.00
GPT-4 Turbo Preview
1020.00±22.00
Gemini 1.5 Pro (April 2024)
1005.00±33.00
Claude 3.5 Sonnet (June 2024)
992.00±25.00
Aya Expanse 32B
983.00±30.00
Gemini 1.5 Flash
980.00±28.00
Gemma 2 27B
951.00±26.00
Llama 3.2 90B Vision Instruct
944.00±24.00
Claude 3 Opus
919.00±22.00
Llama 3.1 405B Instruct
915.00±23.00