Humanity's Last Exam Text Only (Preview)
[hle-text-only-examples]
We report metrics on additional text-only models, evaluated on text-only HLE questions, representing 87% of the dataset. See the multimodal benchmark here.
Introduction
AI capability is evaluated based on benchmarks, yet as their progress accelerates, benchmarks become quickly saturated, losing their utility as a measurement tool. Performing well on formerly frontier benchmarks such as MMLU and GPQA are no longer strong signals of progress as frontier models reach or exceed human level performance on them.
In partnership with the Center for AI Safety, we address the problem of benchmark saturation by creating Humanity’s Last Exam (HLE): 2,700 of the toughest, subject-diverse, multi-modal questions designed to be the last academic exam of its kind for AI. HLE is designed to test for both depth of reasoning (eg. world-class mathematical problems) and breadth of knowledge across its subject domains, providing a precise measurement of model capability. Current frontier models perform poorly on HLE with low accuracies, and systematically exhibit uncalibrated overconfidence in their answers.
We publicly release Humanity’s Last Exam for the research community to better understand model capabilities. Evaluation is low-cost, as questions are precise and unambiguous with closed-ended answers provided – allowing for automatic evaluation. To combat the serious problem of training data contamination and benchmark hacking, we have an additional held-out private set of HLE questions to periodically measure overfitting to the public dataset. More research on overfitting can be found here.
High accuracy on HLE would demonstrate AI has achieved expert-level performance on closed-ended cutting-edge scientific knowledge, but it would not alone suggest autonomous research capabilities or “artificial general intelligence.”
See the linked full paper and dataset.
Methodology
Leaderboard rankings are determined using Rank (Upper Bound), which reflects a model’s statistical position based on confidence intervals. The ranking process follows these steps:
Count the number of models that are statistically significantly better than the target model.
Add 1 to this count to determine the model’s rank.
A model is considered statistically significantly better than another if its lower-bound score (95% confidence interval) is higher than the other model’s upper-bound score.Models receive the same rank when the same number of models are statistically better than each of them. This approach groups models based on statistical significance rather than raw scores, ensuring rankings reflect meaningful performance differences.
Leaderboard Results
HLE is a multi-modal benchmark, our main leaderboard includes only models with multi-modal capabilities. We present an additional benchmark of text-only models on the text-only split below.
We emphasize that as of release, most models do poorly on HLE, meaning small inflections in accuracy are not meaningfully differentiating for model rank within overlapping confidence intervals. Nevertheless, we observe models with inference time reasoning capabilities tend to do better than ones without reasoning.
Dataset Summary
Humanity’s Last Exam includes questions across dozens of subjects across mathematics, humanities, and the natural sciences. We provide a high level visualization of the distribution of the benchmark categories – though there are many subjects within each summarized category.

The benchmark is multimodal, with 13% of questions requiring comprehending a diagram or figure to answer the question. In addition, 24% of the questions are multiple choice.
Dataset Design
Humanity’s Last Exam is a collaborative effort with questions from nearly 1000 subject expert contributors, affiliated with over 500 institutions across 50 countries – composed mostly of professors, researchers, and graduate degree holders. Participants competed for a $500,000 USD prize pool – $5,000 USD for each of the top 50 questions and $500 USD for the next 500 questions, along with the opportunity for optional co-authorship if any question is accepted in the final dataset. This structure incentives top questions from subject experts all around the world. More details can be found in our original announcement: https://scale.com/blog/humanitys-last-exam.
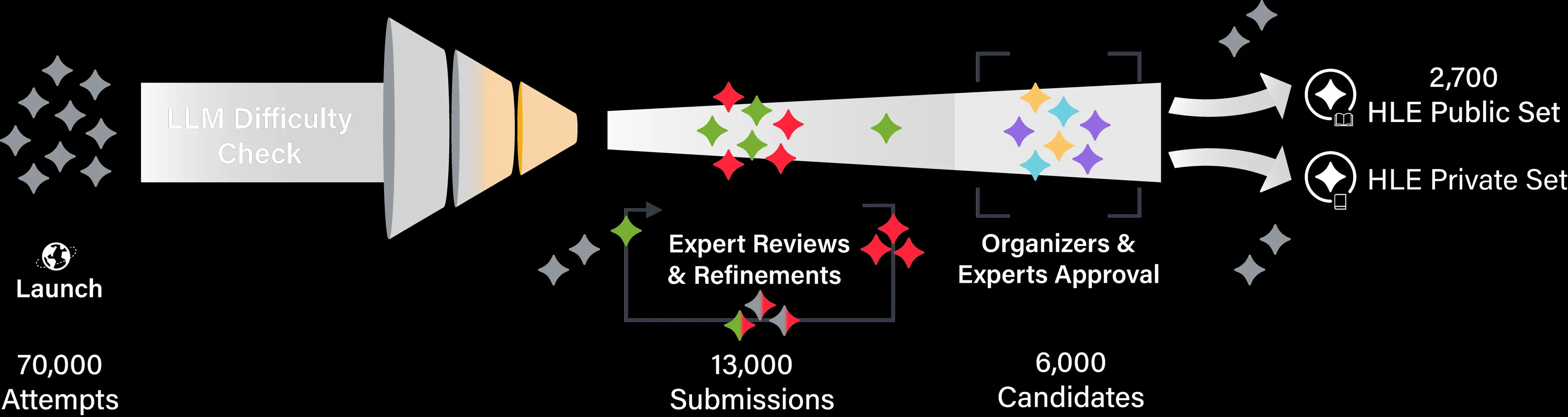
Submission: Submitted questions must stump several frontier LLMs for exact match questions, or allow only up to random chance across all LLMs for multiple choice questions to be considered for human review. This ensures the questions are of a necessary difficulty bar for the current generation of models, we further verify they are sufficiently difficult with human review. In total, we received over 70,000 submissions, with 13,000 passing this difficulty bar and forwarded to human review.
Human Review: We train experts sourced from Scale’s Outlier platform to review questions. All of the human reviewers have a graduate degree in their field. Reviewers score questions against a standardized rubric, providing feedback to help question creators iterate questions. A primary round is used to shortlist the best questions. A secondary review with both organizers and expert reviewers approves or rejects questions from the final dataset – resulting in 2,700 public questions and an additional set of private questions of equal quality and difficulty.
Metrics
We report both the accuracy on public questions of Humanity’s Last Exam and use the model’s own stated confidence to derive an RMS calibration error using the implementation from Hendrycks et al., 2022 with the default hyperparameters provided, reported in our paper for brevity. Models are ranked on the leaderboard using accuracy, however we want to emphasize calibration errors as an important metric in our paper.
A well-calibrated model should exhibit an average confidence similar to its accuracy on a benchmark - eg. 50% accuracy paired with 50% confidence. As of our initial publication, we observe systematic high calibration errors (greater than 80%) paired with low accuracy (less than 10%), which indicates strong evidence for confabulation/hallucination in all measured models.
Details on our evaluation methodology found below. At this time, we do not report any model performance metrics on the private held-out set.
Evaluation Methodology
Evaluation is automatic. Each model on the leaderboard is evaluated on all public questions of Humanity’s Last Exam with temperature 0.0 when configurable or stated otherwise. Models are prompted to give a final answer and an estimation of confidence using the system prompts (or user prompt when not configurable) below depending on question type, following the setup from Wei et al., 2024.
[hle-questions]
As HLE uses closed-form solutions, we use o3-mini-2025-01-31 as an automatic extractor and judge to compare the model response against the ground truth answer. We employ structured decoding to extract a JSON from the following prompt. We note small differences could arise from different judge models and prompts used on edge cases (eg. acceptable precision), hence we encourage the documentation of prompts and models used for evaluation on HLE. We document ours for this evaluation below.
[hle-prompts]
Acknowledgements
Humanity’s Last Exam was a global collaborative effort developed in partnership with the Center for AI Safety. We extend our deepest gratitude to all participating question contributors and expert reviewers involved in creating and refining the Humanity’s Last Exam dataset.
Scale AI Team: Ziwen Han, Josephina Hu, † Hugh Zhang, Chen Bo Calvin Zhang, Mohamed Shaaban, John Ling, Sean Shi, Michael Choi, Anish Agrawal, Arnav Chopra, William Qian, Luis Esquivel, Caton Lu, Monica Mishra, Summer Yue, Alexandr Wang
Performance Comparison
18.57±1.57
13.97±1.40
11.10±1.26
8.61±1.13
DeepSeek-R1
8.57±1.13
8.44±1.12
8.35±1.11
7.05±1.03
6.67±1.00
6.58±1.00
6.24±0.97
Llama 3.2 90B Vision Instruct
5.53±0.92
5.23±0.90
5.15±0.89
Gemini 2.0 Flash Experimental (December 2024)
4.89±0.87
4.89±0.87
4.85±0.86
4.81±0.86
Qwen2-VL-72B-Instruct
4.73±0.85
4.60±0.84
4.43±0.83
o1-mini*
4.05±0.79
Claude 3 Opus
3.97±0.79
Gemini-1.5-Flash-002
3.84±0.77
2.62±0.64
Rank (UB): 1 + the number of models whose lower CI bound exceeds this model’s upper CI bound.
-