Agentic Tool Use (Enterprise)
Introduction
The ability of agentic LLMs to chain multiple tool calls together compositionally to solve tasks is an open problem. The ToolComp benchmark comprises 485 meticulously crafted prompts & final answers designed to evaluate the proficiency of AI models in tasks necessitating dependent tool usage. This benchmark is distinguished by prompts that require composing multiple tools together, golden answer chains, and process supervision labels, to create a more thorough & accurate evaluation of an AI model's reasoning and tool-calling abilities. We break up ToolComp into two subsets, one called ToolComp-Enterprise which tests usage of 11 tools and another called ToolComp-Chat which tests usage of 2 common chatbot tools (Python Interpreter and Google Search).
In comparison to other benchmarks in the field, such as ToolBench, API Bench, and API-Bank, ToolComp critically combines compositional tool use with human-verified final answers, which can be evaluated automatically. Existing benchmarks either lack dependent tool usage, final human-verified answers, or rely on artificial tools with limited outputs, failing to provide scenarios that truly mirror the sequential and interdependent tool use required in real-world, enterprise settings. This omission leads to a gap in effectively providing granular feedback for localizing errors, making incremental improvements and enhancing AI capabilities in real-world applications, where complex, step-by-step reasoning and the execution of multiple dependent tools are essential to get to a final correct answer. A summary of the contributions and metadata for existing tool use benchmarks is provided in Table 1.
To bridge this gap and better align the needs of AI applications with the capabilities of benchmarks, we introduce ToolComp, a tool-use benchmark designed to meet the evolving demands of agentic model makers seeking to rigorously test and scale their models in practical, dynamic environments.
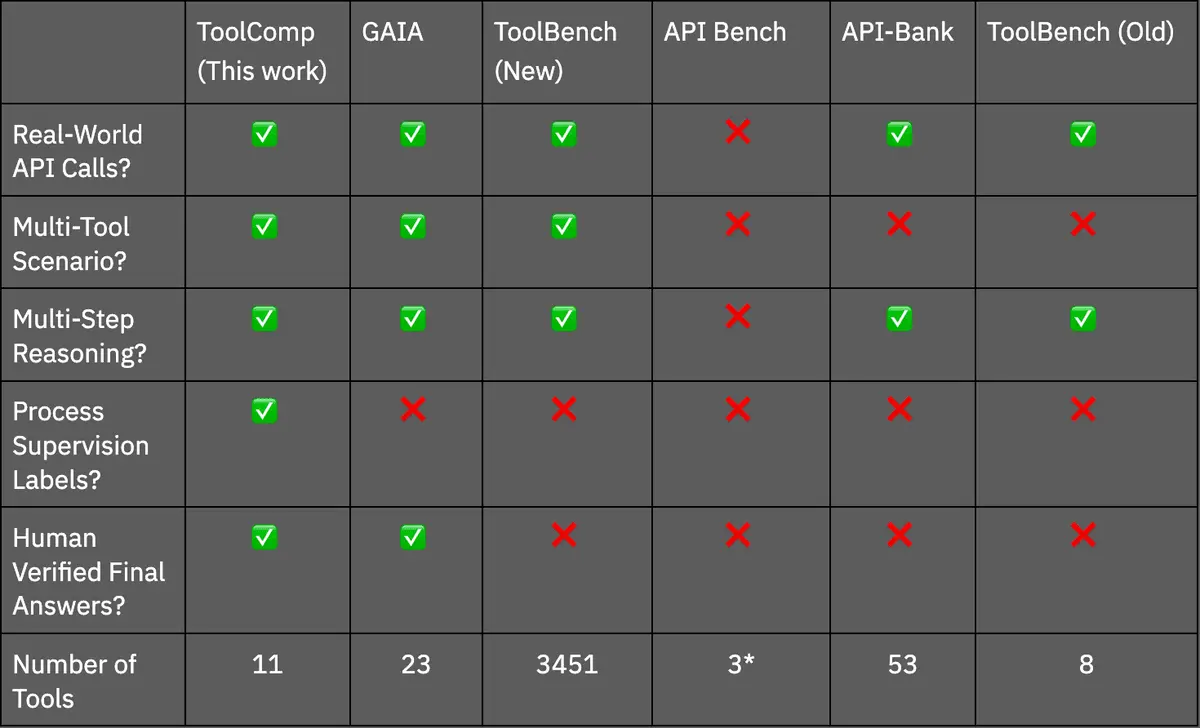
Table 1. The contributions and metadata of popular benchmarks in Tool Use. Our work, ToolComp, is shown in the first column. *Although APIBench technically only uses only 3 tools, its novelty comes from having hundreds of possible APIs to use in Python.
Dataset Description
ToolComp consists of 485 examples of prompts and labels containing examples of dependent tool calling, as shown below. We define dependent tool calling as the need to call multiple tools in sequence such that the output of a previous tool must be used to motivate the input for a subsequent tool. Note that the action_input for the finish action is the final answer.
[tool-use-data-1]
[tool-use-data-1]
Figure 1. Examples from ToolComp of prompt and their corresponding correct chain of dependent tool calls that get to the correct answer. The Assistant is asked to generate a high level action plan on how to get to the final answer as well as take a step by step approach using the ReAct format to make a sequence of dependent tools calls to reach the final answer. Additionally, each of the model generated substeps (Thought, Action and Action Input) is annotated with process supervision labels. If the step was corrected, the original incorrect step that was corrected is marked as a bad step. All other steps including steps that were marked as correct by the annotator and steps that an incorrect step was corrected to are marked as correct.
In creating the benchmark, we developed two subsets, ToolComp-Enterprise and ToolComp-Chat. ToolComp-Enterprise contains 11 tools and aims to emulate settings in which LLM agents must compose a larger number of expressive APIs together correctly, such as in enterprise settings. The second subset, ToolComp-Chat, is designed to test general purpose chatbots with the minimally sufficient set of tools for information retrieval and processing tasks, namely Google Search and Python Interpreter. The ToolComp-Chat setting leverages only web search and python execution as these are standard tools found in major chatbot providers. We only allow the respective tools for each subset during prompt generation, labeling, and evaluation.
ToolComp-Enterprise contains 287 examples while the ToolComp-Chat subset contains 198 examples. Each of the 11 tools are described below in Figure 3.
[tool-use-data-1]
Prompt Creation
We utilized a hybrid synthetic approach leveraging Seed prompts to generate intermediary prompts which were then edited and improved using humans-in-the-loop. The overall process is described in more detail below.
Step 1: Develop In-Context Examples We crafted high-quality in-context examples with corresponding reasonings, which we call ‘processes’, to guide prompt generation. An example is illustrated in Figure 2 of Appendix C.
Step 2: Generate Initial Prompts Using the in-context examples, we generated synthetic prompts, ensuring diversity by selecting random subsets of the IC Examples. Each subset used distinct in-context prompts and randomly sampled tools from its set of available tools. The Seed prompt used in this step is shown in Appendix A.
Step 3: Human Refinement Annotators reviewed the prompts to resolve any issues related to complexity, clarity and ambiguity. We gave clear instructions on ambiguity (only one possible correct answer) and complexity (requires two or more tool calls to answer), instructing our annotators to ensure the prompt has only one correct answer that is complex, challenging and requires the use of tools.
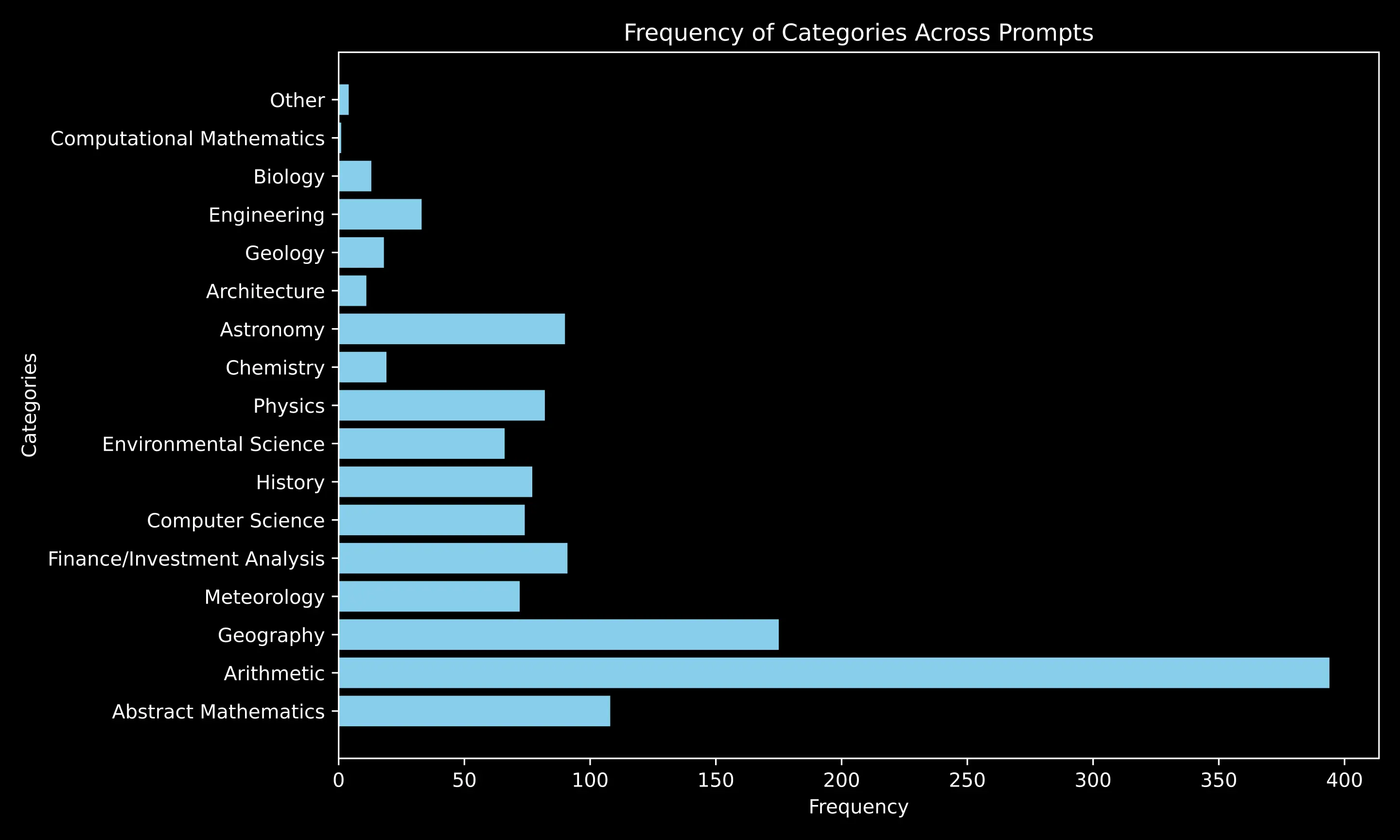
Figure 4. Here, we show the various topics our prompts address. Many prompts require arithmetic operations and mathematical reasoning along with a somewhat uniform distribution of multiple disciplines ranging from Geography, Finance, History, Physics, Chemistry, Astronomy, Architecture etc. The topics are not mutually exclusive since many of these prompts span multiple domains and require multiple tools, multiple sources of knowledge and diverse forms of reasoning.
Label Creation
To create the process supervision labels as well as the final answer for each prompt, we utilized a hybrid human-AI approach. We start by prompting an LLM to outline a plan on which tools to call and in what order to get to the final answer. We then append this plan, which we call the Action Plan, to the sequence before using the LLM to formulate tool calls. This gives it a high level plan that it can try to execute with tool calls. We then use the LLM to call tools in the ReAct format. We chose this as it is the de facto standard for tool use and agentic workflows that combines reasoning and tool calls.
We asked the annotators to rate if a step is Correct, meaning that it is a reasonable step to getting closer to the final answer, or Incorrect, meaning the step is nonsensical, incorrect, or is not reasonable in getting to the final answer. The Action Plan as well as each of the ReAct steps must be marked as Correct or Incorrect by the annotator. If the annotator marks a step as Correct, the model is allowed to proceed further and generate the next step. If the annotator marks a step as Incorrect, they then edit the step to be correct. The model is then prompted to go further to the next step with the human-edited step as part of its context. This is repeated until the Finish Action is chosen by the LLM and marked as Correct by the annotator or until the annotator corrects an Action step to ‘Finish’ because we have enough information to answer the question. The overall flow is shown below in Figure 5:
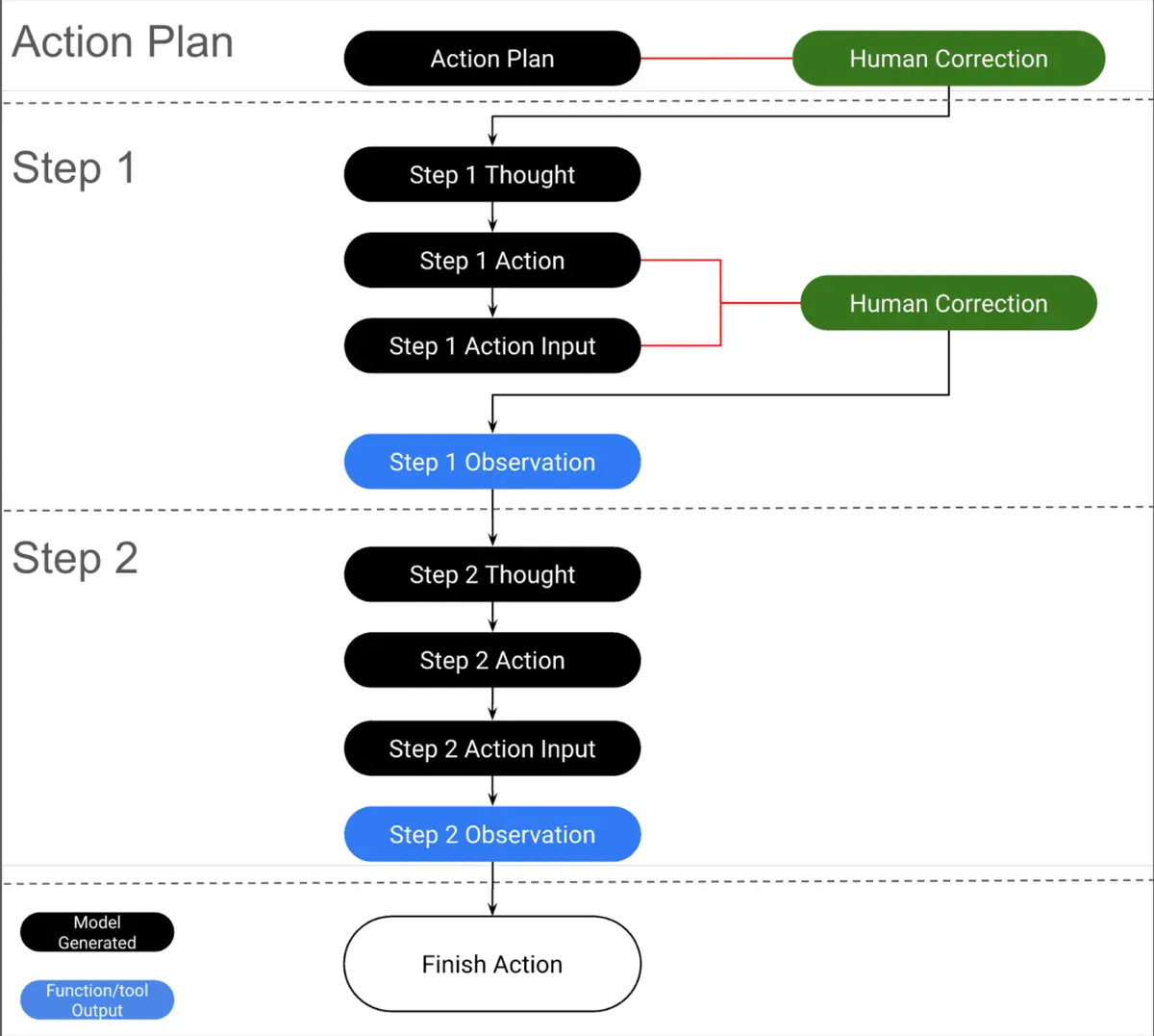
Figure 5. The overall diagram of the human-AI collaborative process employed to create the process supervision labels and the final answer for each prompt.
After this process, our final data set includes one valid step-by-step chain of tool calls that successfully gets to the final answer, as well as potential incorrect sub-steps and each step. This yields process supervision labels with correct steps and incorrect steps for each prompt.
Note that for each tool subset, we only allow the LLM and the annotators to use the allowed tools for that subset.
Benchmark Metadata
Complexity. We define complexity as the number of tools required to solve a query/prompt. We show the complexity distribution, i.e. the number of tool calls, of ToolComp prompts in Figure 6.
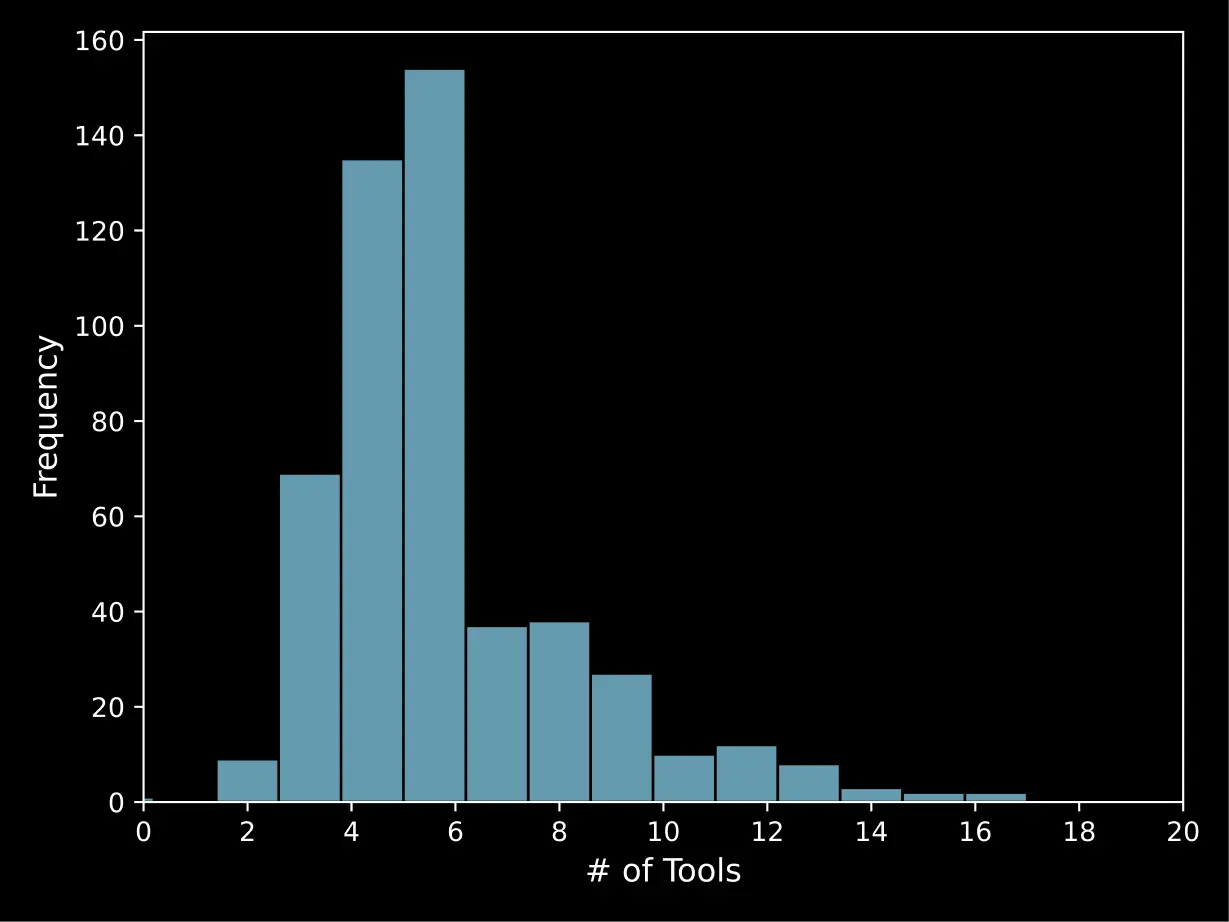
Figure 6. About 85% of prompts in ToolComp require at least three tools to solve, indicating that they have a decent amount of complexity and difficulty. Furthermore, ~20% of prompts still require seven or more tool calls to solve. This indicates that an agent being evaluated on this benchmark requires high context length, sophisticated reasoning over long context, and advanced tool calling capabilities in order to process long tool chains, formulate a high level plan, and understand the outputs of each tool call to proceed to the next step and subsequently achieve a high score.
Answer Character Length. One simple way to quantify the final answers’ structure is to count their character lengths. We show the distribution of character lengths in ToolComp’s final answers in Figure 7. For more unambiguous evaluations, we focus on shorter character lengths with integers and short strings that are easy to verify.
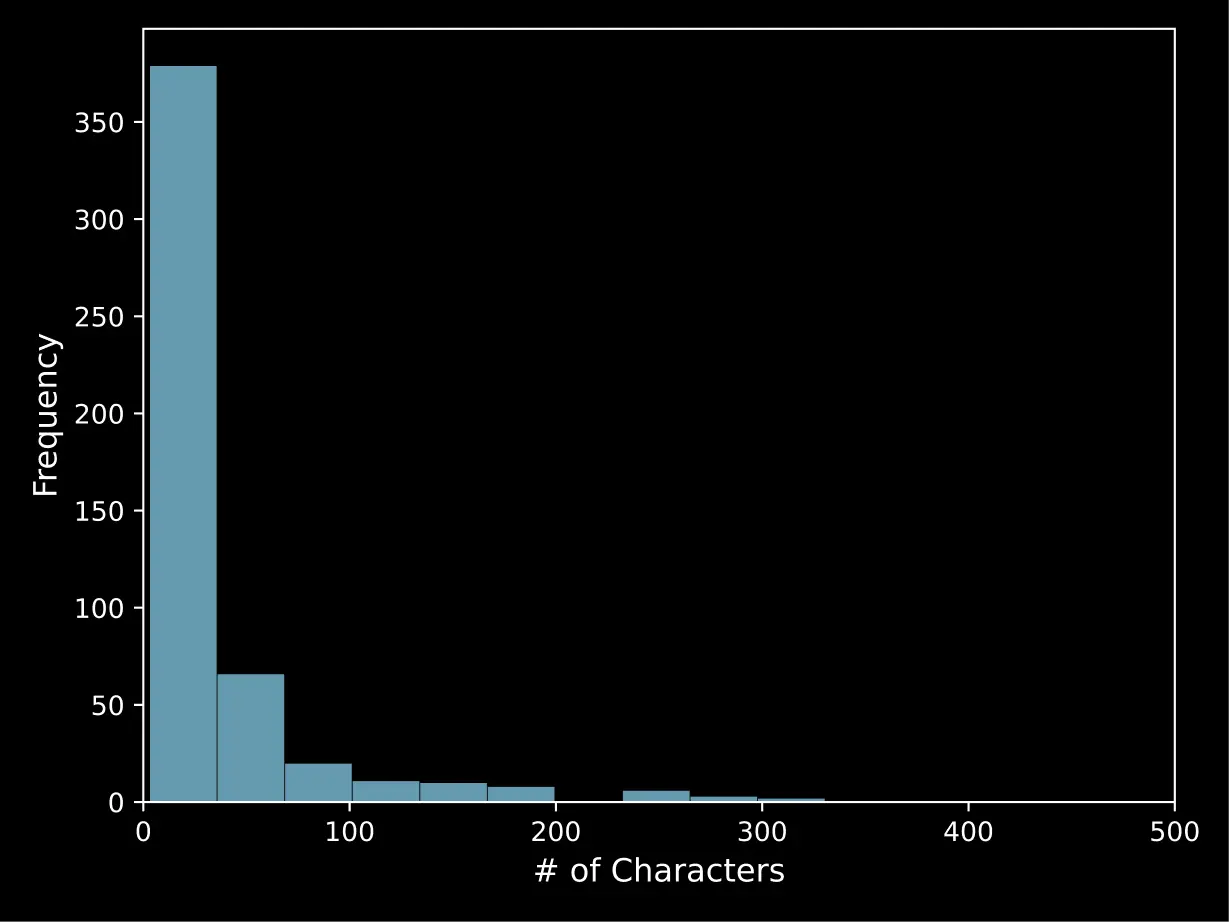
Figure 7. Due to the nature of ToolComp needing to have answers that are easily verifiable, we choose to create prompts that have numbers and short strings to match. However, there are still some examples of prompts that require long structured outputs such as dictionaries, tuples and lists. These test the agent’s ability to follow complex queries that involve returning long outputs such as lists or dictionaries of city names, temperatures, altitudes, etc.
Answer Types. Below is the distribution of the following primitive data types: number, text, and date. We care most about evaluation of compositional tool use and reasoning rather than aesthetic output structuring and formatting. This is why the benchmark's labels are predominantly numeric while containing a significant fraction of string outputs. In many cases, strings and names are intermediary outputs, but we most often ask for numerical final answers to make the answer easier to unambiguously verify.
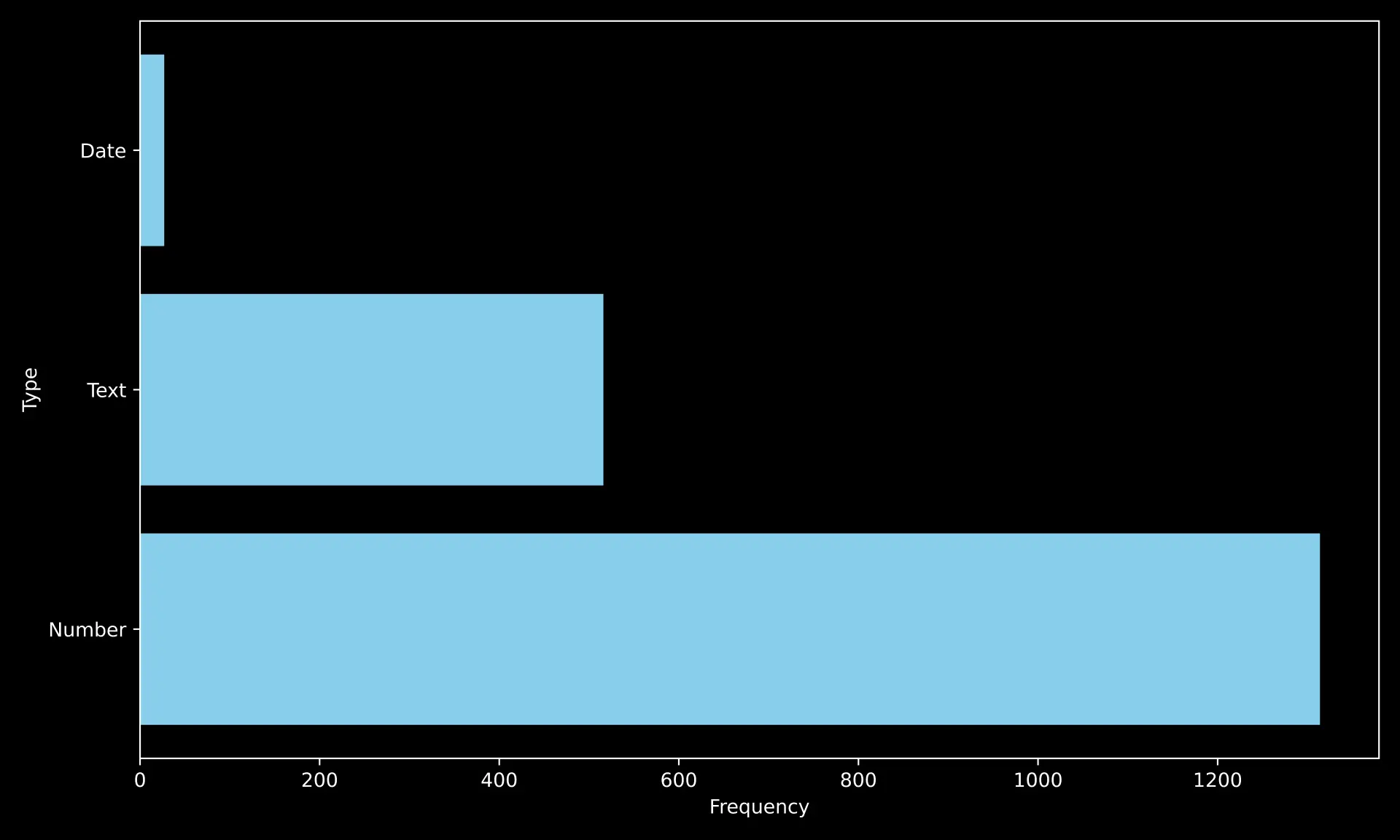
Figure 8. The figure above shows the distribution of various data types in our benchmark.
Evaluation Metric
We have two metrics to evaluate the quality or the correctness of a model’s final answers: LLM Grading and Exact Match. For our main leaderboard, we use LLM Grading to ensure that we only check whether the answer is correct without penalizing formatting issues. Our Exact Match evaluation methodology is shown below in Appendix D: Exact Match.
LLM Grading
By using LLM grading against ground truth answers we opt to be charitable to exact formatting and focus on assessing the tool use capabilities of the model. We intentionally choose not to focus on final answer formatting given that (1) there are existing benchmarks that assess formatting ability (e.g. FOFO) and (2) our final answers are quite complex, containing multiple elements, lists which may or may not be sorted, and dictionaries. This approach prompts an LLM Judge to look at the prompt, the ground truth answer, and the model’s answer and asks the model to classify it as Incorrect, Correct with bad formatting or Correct. We use GPT-4-Turbo as the de-facto judge for all of our models. The prompt used is shown in Appendix B: LLM Grading Prompt. We consider both Correct and Correct with Bad Formatting as a win (accurate) and Incorrect as a loss (inaccurate).
Evaluation Results
We evaluate different models in getting to the final answer and predicting our process supervision labels. Since evaluating final answers tests actual tool calling capabilities, we show these in our main leaderboard.
We acknowledge that each LLM was trained in a specific format to generate the arguments as well as process the outputs of arbitrary functions/tools. Under this assumption, we use native function calling for each respective model to give it a fair shot at performing its best on this benchmark.
For the avoidance of doubt, the evaluated model is what generates the high level action plan, performs native function calling, and derives the final answer. The grading model (GPT-4 Turbo in our case), is then used to evaluate the model’s output by comparing it against the ground truth answer.
As mentioned previously, we have 2 subsets to evaluate these models on:
The first we call the “11-tool” or “ToolComp-Enterprise” subset, where the agent has access to all 11 tools shown in Table 2. This is called the “ToolComp-Enterprise” subset because the agents must choose from a larger set of more specialized, real tools, as would be common in enterprise LLM applications
The second we call the “2 tool” or “ToolComp-Chat” subset, where the agents only have access to two tools: Google Search and Python Interpreter. We call this the ToolComp-Chat subset because leading chatbots are usually natively endowed with these two tools. In this setting, the LLM is tested on formulating search queries to find and retrieve relevant information as well as using that information in the Python Interpreter to do calculations, use symbolic solvers, process & manipulate data, write code, etc.
Process Supervision Evals
We further evaluate these models using our process supervision labels, aiming to assess each model's effectiveness as a pairwise judge in selecting the human-corrected step over the step generated by the original policy used during annotation. To mitigate position bias, we swap the order of the human-corrected and model-generated steps and conduct two separate predictions for each arrangement. Additionally, models are permitted to indicate a tie. If a model designates a tie at least once, or consistently predicts the same position (before and after swapping) for a given data sample, we classify the outcome as a tie. Mirroring the methodology used in RewardBench, we score losses as 0, ties as 0.5, and wins as 1.
Error Analysis
In order to better understand the reasons behind each model’s failures, we come up with an Error Taxonomy and use GPT-4 Turbo to categorize the reasoning behind each failure. We inspect the individual failure cases predicted by GPT-4 Turbo and find that it is reasonably accurate. The different categories and their definitions are shown below in Table 3.
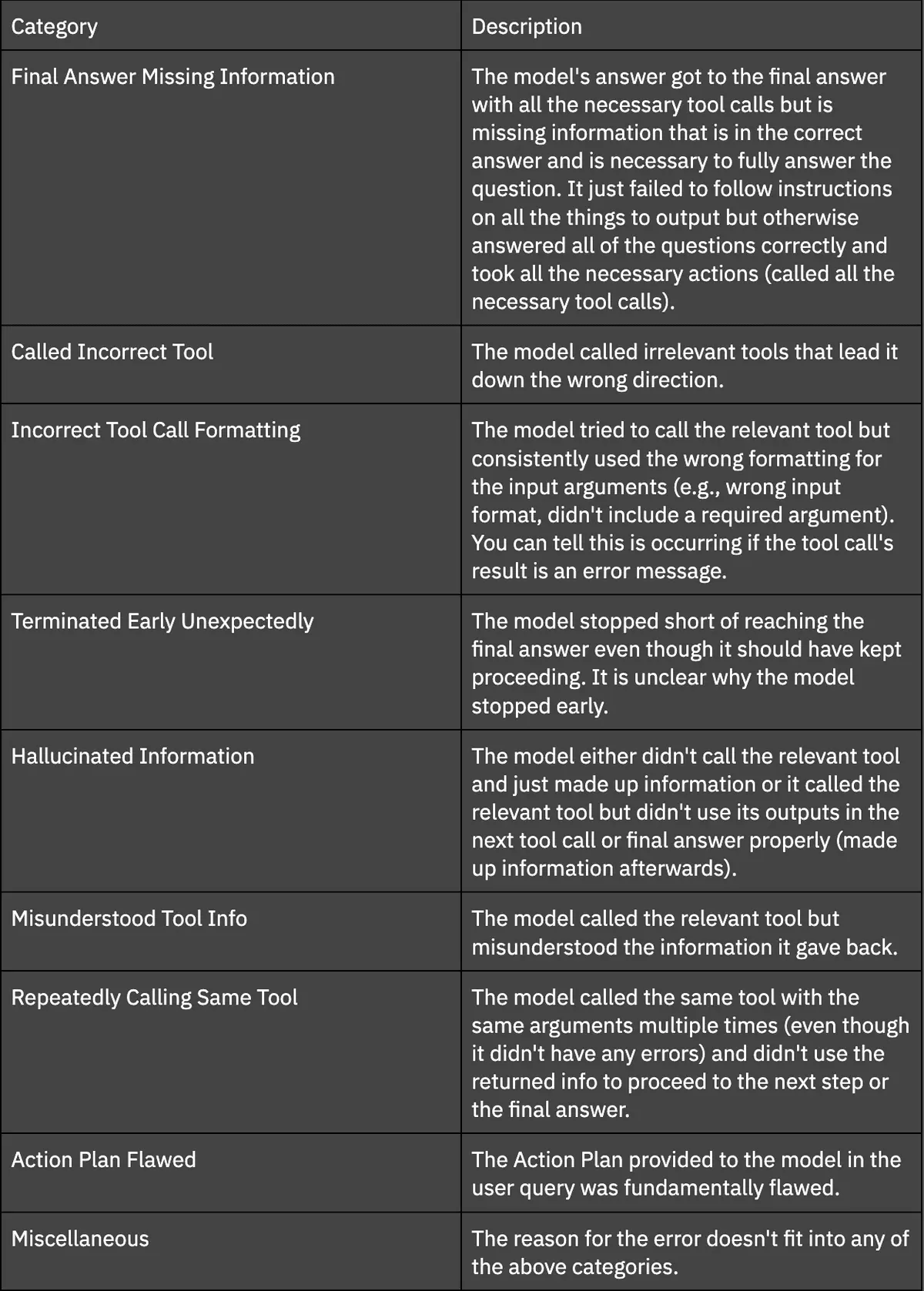
Table 3. The accuracy of various models with their native function calling format and LLM Grading is shown above. The black bars show 95% confidence intervals for proportions with a binomial exact match calculation.
Appendix
A. Seed Prompt
[data-example-tools-2]
B. LLM Grading Prompt
[data-example-tools-3]
C. IC Example
[data-example-tools-4]
A single IC example and its process/reasoning. Both are used in the synthetic prompt generation process.
D. Exact Match
This paradigm aims to assess both the tool use capabilities and the instruction/format following capabilities of the model. Formatting is particularly important when we want to use the LLM to automate a backend process. This paradigm programmatically evaluates unsorted lists (eg. prompt asks for a list of all states in the US), sorted lists (eg. prompt asks for a list of all states in the US in alphabetical order), numbers (eg. prompt asks for the areas of Texas in square miles), and strings (eg. prompt asks for the name of the football team that won the Superbowl in 2016).
Unsorted lists are sorted and exact matched (set match gets rid of duplicates)
Sorted lists are exact matched
Number are checked if they are within a tolerance param (the tolerance param is to account for variance among different sources online)
String are stripped, lower cased, and exact matched
Performance Comparison
o1 (December 2024)
70.14±5.32
68.75±5.35
67.01±5.43
o1-preview
66.43±5.47
DeepSeek-R1
65.27±5.49
o3-mini (high)
65.27±5.52
Claude 3.7 Sonnet Thinking (February 2025)
65.27±5.49
Claude 3.7 Sonnet (February 2025)
64.93±5.51
o3-mini (medium)
64.93±5.51
GPT-4o (May 2024)
64.58±5.52
64.23±5.53
GPT-4.5 Preview (February 2025)
63.76±5.56
Gemini 2.0 Flash Thinking Experimental (January 2025)
63.19±5.57
DeepSeek-V3 (December 2024)
62.50±5.59
Gemini 2.0 Pro Experimental (February 2025)
61.45±5.62
GPT-4 Turbo Preview
60.76±5.64
Gemini 1.5 Pro (August 27, 2024)
60.28±5.66
Gemini 2.0 Flash Experimental (December 2024)
60.07±5.65
GPT-4o (August 2024)
59.93±5.67
Claude 3.5 Sonnet (June 2024)
59.38±5.67
Gemini 2.0 Flash
55.60±5.73
Claude 3 Sonnet
54.17±5.78
Gemini 2.0 Flash Lite Preview (February 2025)
53.82±5.75
Claude 3 Opus
52.78±5.77
GPT-4o mini
51.74±5.77
GPT-4
51.39±5.77
Llama 3.1 405B Instruct
50.35±5.78
Mistral Large 2
50.35±5.78
Nova Pro
47.04±5.77
Gemini 1.5 Pro (May 2024)
40.42±5.68
Llama 3.1 70B Instruct
37.23±5.60
Nova LIte
36.53±6.72
Command R+
30.21±5.30
Nova Mirco
28.93±6.33
Llama 3.1 8B Instruct
17.42±4.39
Rank (UB): 1 + the number of models whose lower CI bound exceeds this model’s upper CI bound.