Machine Perception for Human Protection: Creating Vision Algorithms to Augment Perimeter Security

Computing advances of the past decade have given us new forms of machine perception that can enhance our security posture and augment human capabilities. To apply this technology to perimeter security, Scale AI has spent the last year working with the Defense Innovation Unit (DIU) and the United States Air Force (USAF) to train horizontal computer vision (CV) models designed to detect and classify maritime vessels. These models are a core component of a greater autonomous perimeter security (APS) perception system that is truly edge-deployable; all computing, detection, and alerting happens without any external network or power connection, anywhere in the world.
Overview
American national defense is predicated on detecting and accurately identifying potential threats to our security. Without technology, this process required constant human attentiveness and considerable personnel needs. This Scale developed model provides greater perimeter security by watching, detecting, identifying, and alerting the necessary units when an unauthorized vessel enters restricted waters autonomously, without any external public network or power connection, all without any increase in manpower.
Scale developed a task-specific model that could identify the watercraft in this particular scenario to incorporate computer vision (CV) into the greater perimeter security perception model,
To apply this technology Scale AI has spent the last year working with the Defense Innovation Unit (DIU) and the United States Air Force (USAF) to develop computer vision (CV) models that can detect and classify maritime vessels. Of note, our computer vision algorithm acts as the eyes within the greater autonomous perimeter security (APS) system that is edge-deployed, closed-loop, and expeditionary. All computing, detection, and alerting happens without any external public network or power connection. Within the greater APS system, detections from our vision algorithm trigger alerts when an unauthorized vessel loiters in restricted waters that are part of the military installation.
While some open-source CV models include some maritime vessels in their ontologies (the set of things that a model is trained to detect), none are capable of reliably distinguishing between authorized U.S. military vessels and unauthorized commercial and recreational watercraft moving about a waterway.
Like all forms of artificial intelligence, a computer vision model’s performance is strongly correlated with the volume of high-quality training data provided. Traditionally, model training requires collecting petabytes of imagery, annotating (or “labeling”) millions of objects within that imagery, and then providing this labeled data to an algorithm so that it can “learn” the visual signatures of all of the relevant objects. With no existing high-fidelity, high-quality labeled data available for this project that describes maritime vessels, the only path to an effective model for this mission set was to collect and label relevant data from scratch.
The Process
During preliminary testing, it was determined that existing, open-source CV models for this problem-space were not able to detect maritime vessels at a sufficient level of fidelity to differentiate between authorized and unauthorized vessels. Open-source CV models produced so many false positives that the algorithms generated more false alarms than useful alerts. This proved to overburden the already busy security force on base.
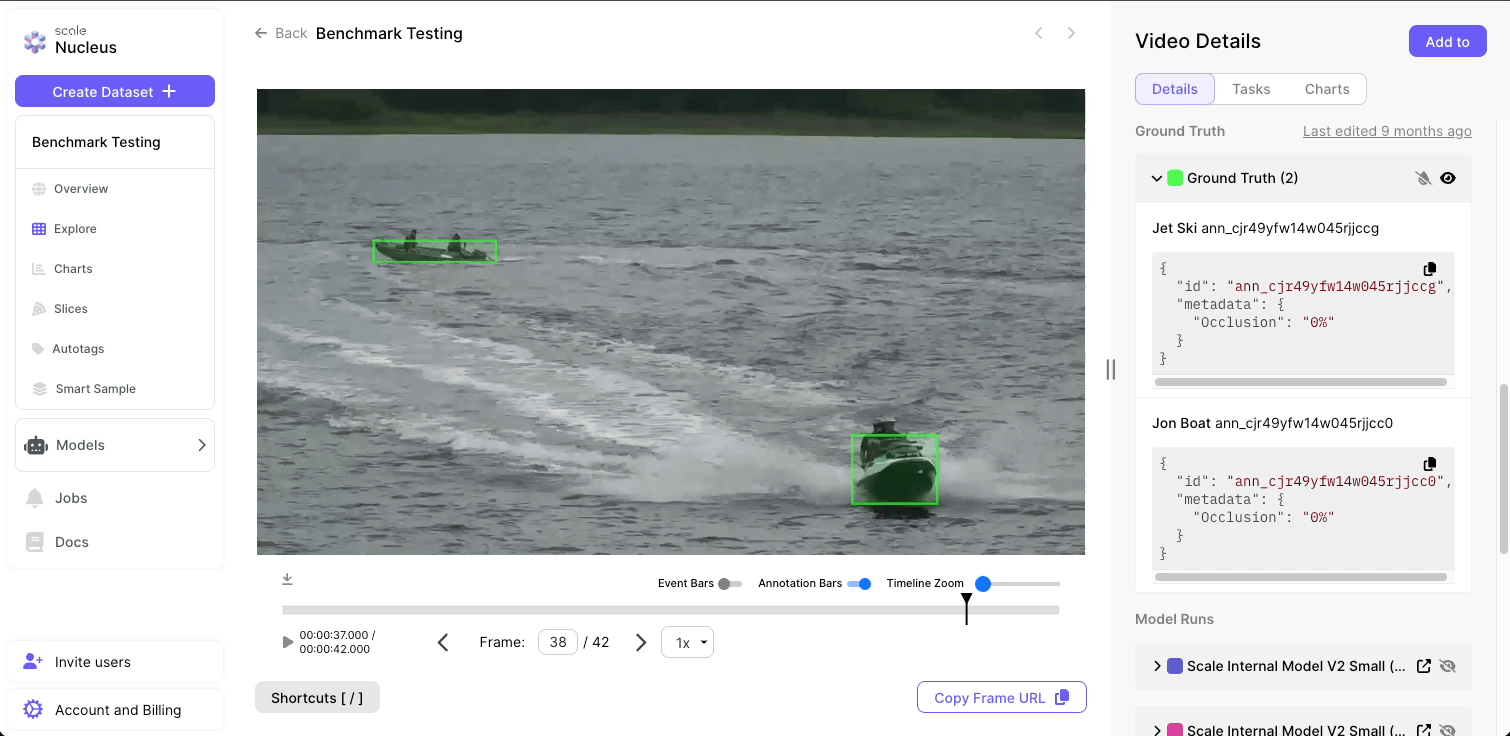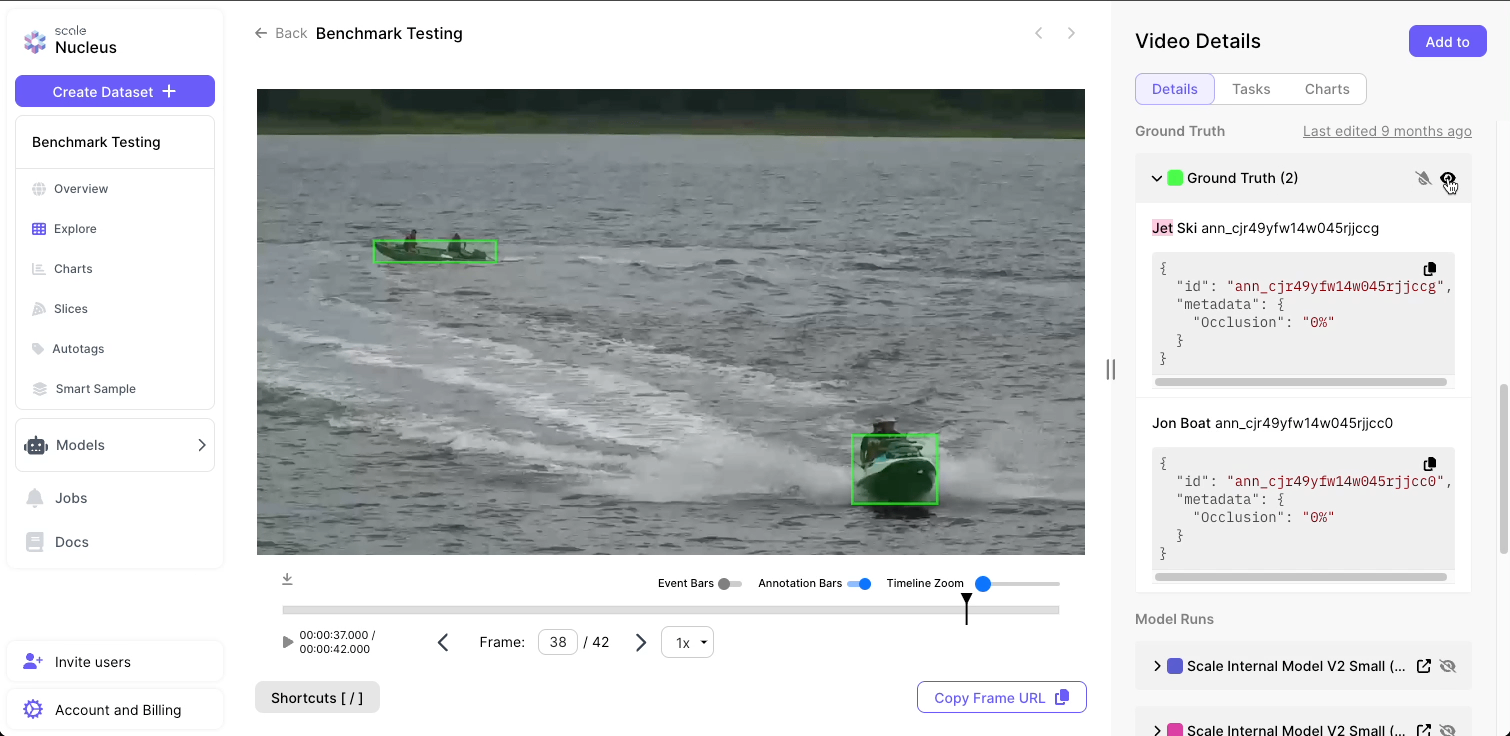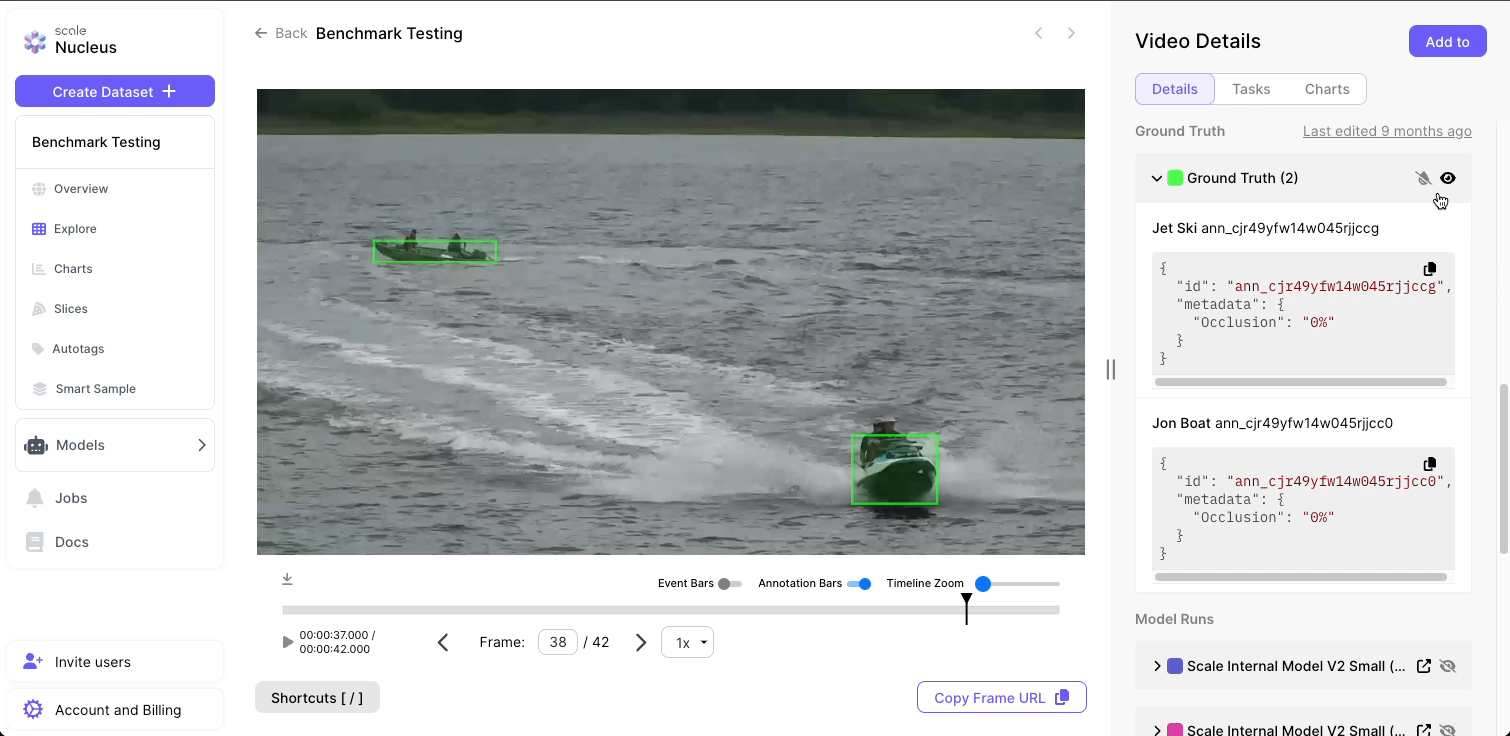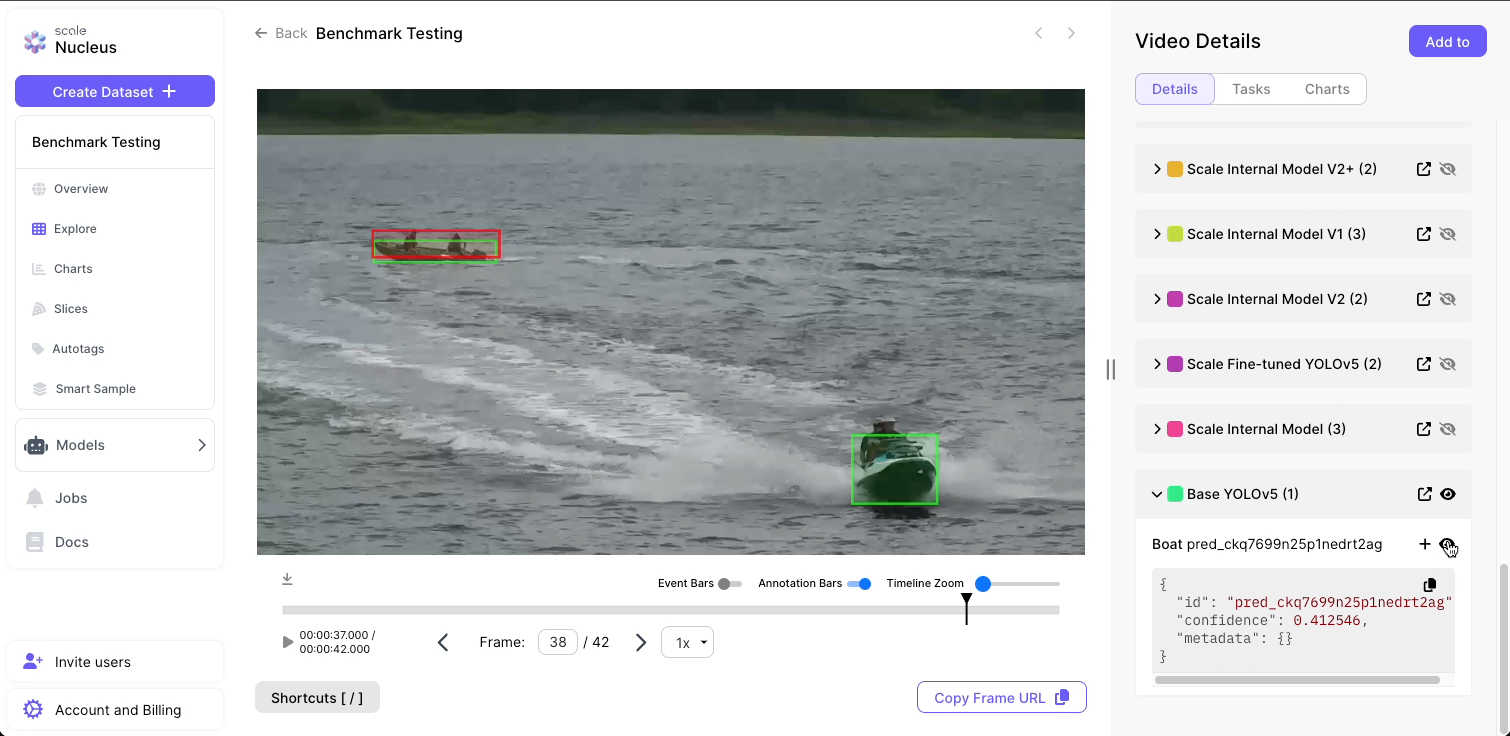
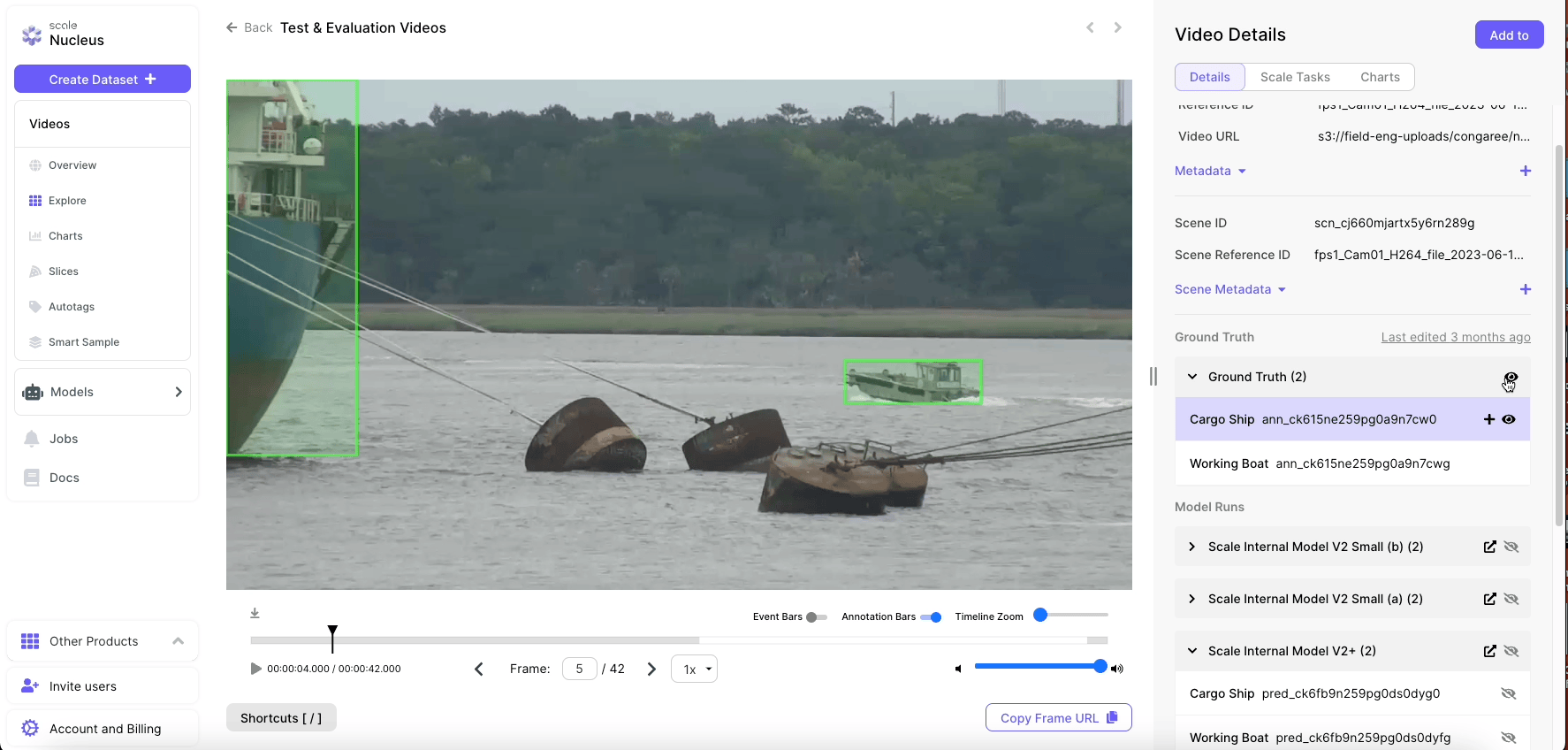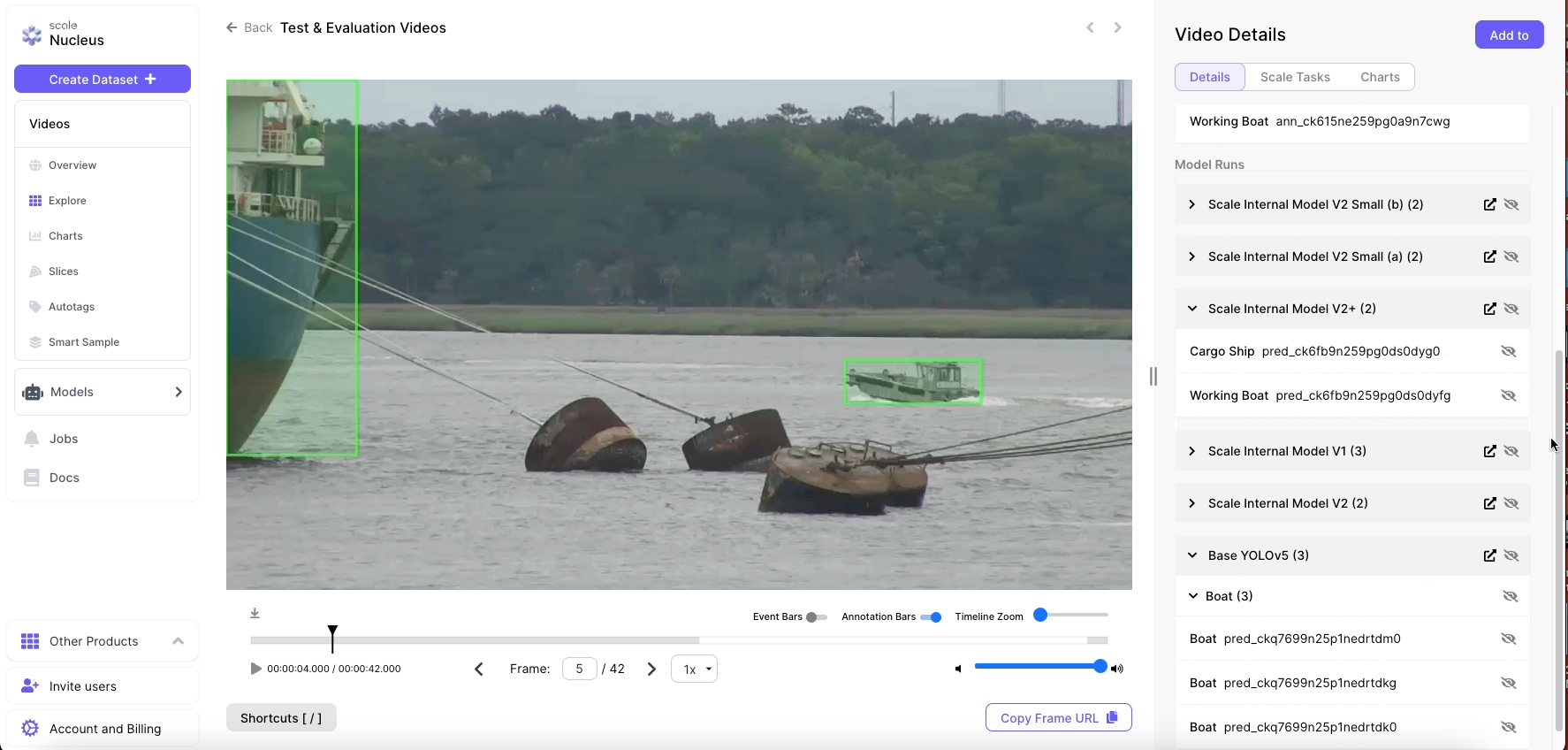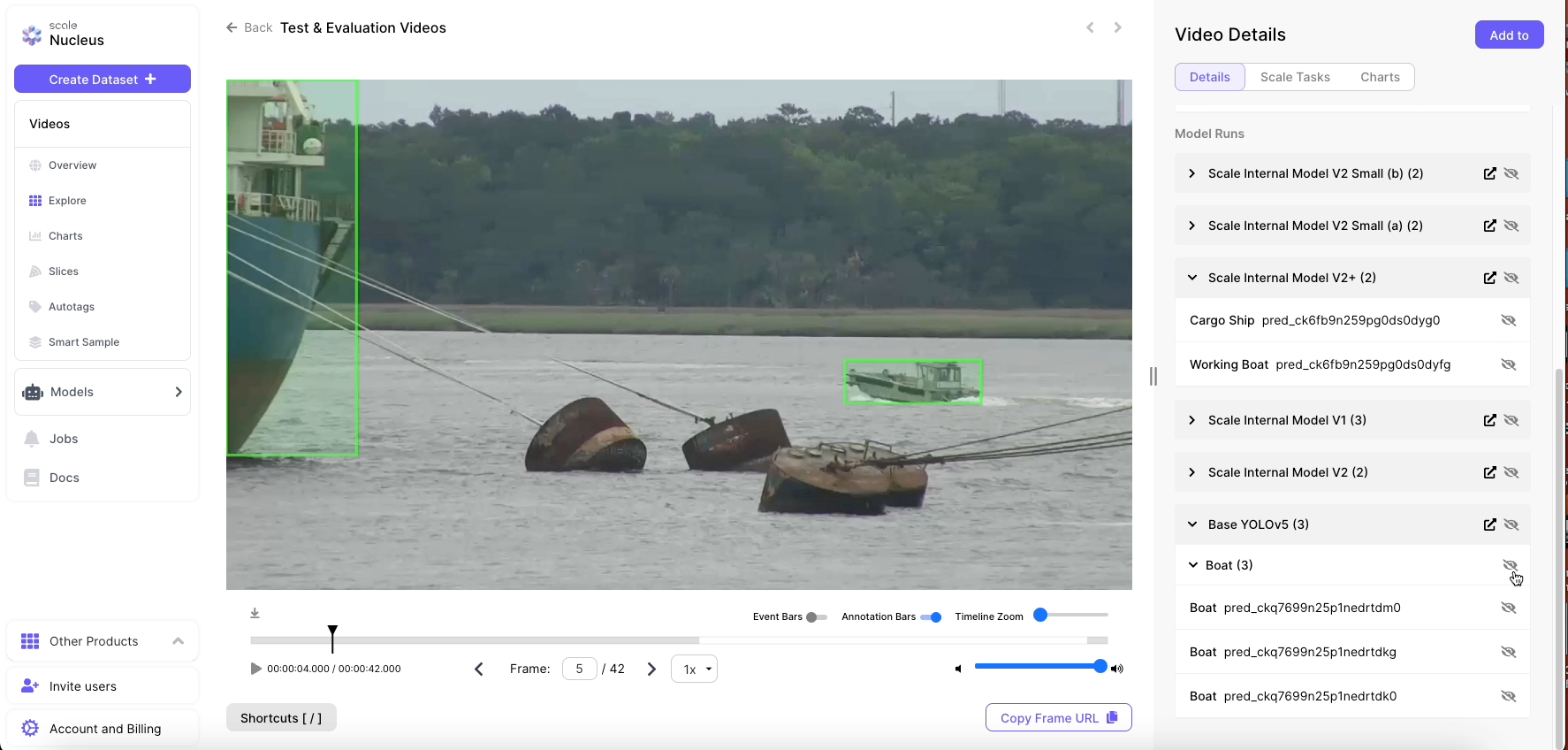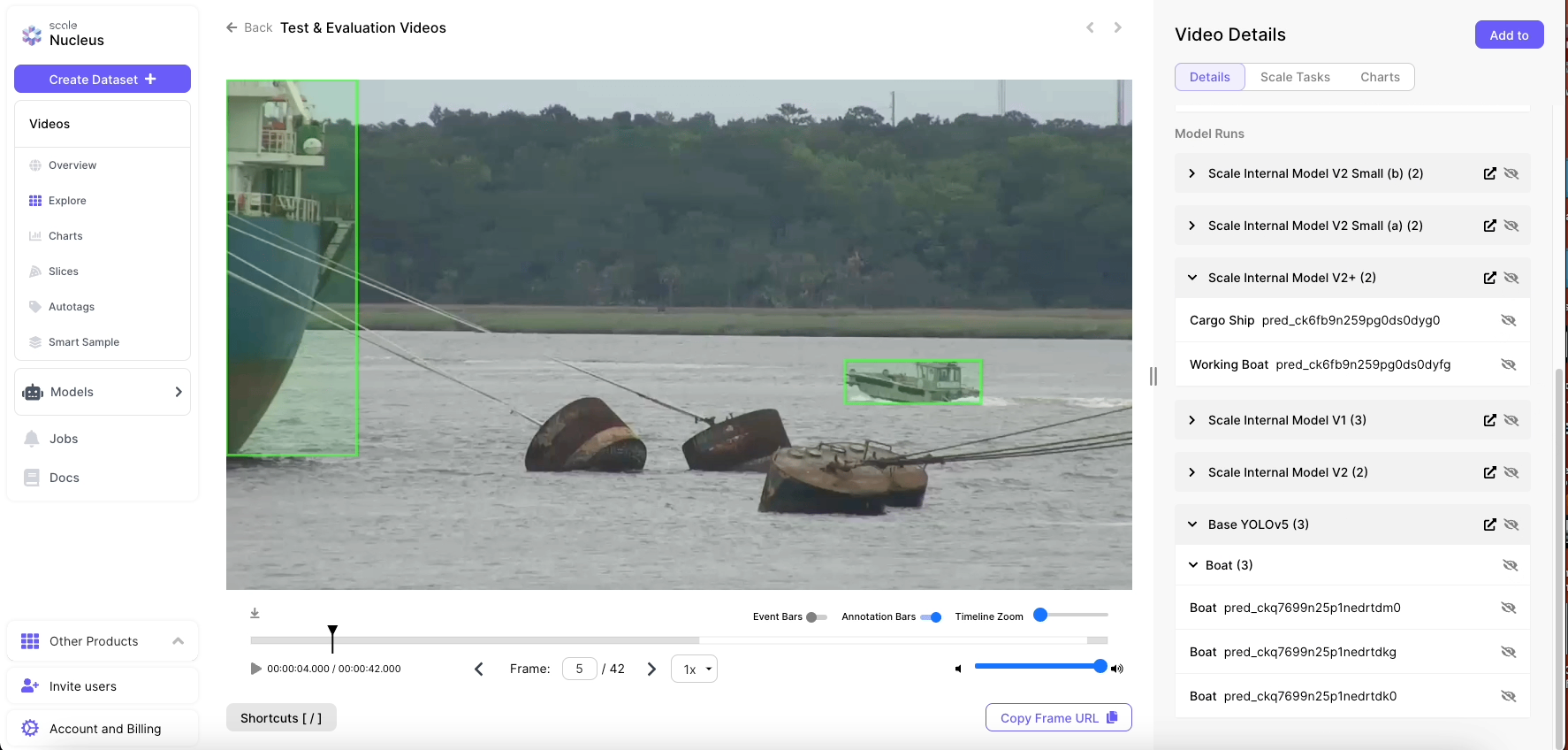
Scale developed an effective CV model in a timely and cost-efficient manner by conducting the full cycle of the Machine Learning Operations (MLOps), including data curation, data labeling, model development and training, and model performance test and evaluation. Scale conducted two rounds of MLOps on training data that came from Full Motion Video (FMV) capturing activity in a USAF waterway. Roughly 88,000 objects were labeled against a bespoke maritime vessel ontology that includes all of the vessel classes seen, ensuring that the models produced for this effort were mapped to the problem and environment at hand.
During the first development sprint, Scale curated video clips from the raw FMV collected at the military installation and created a bespoke dataset with approximately 44,000 labeled objects. Scale’s in-house operations team annotated these frames, differentiating between the vessel types commonly seen in coastal waterways. This highly-specialized dataset was used to train a model designed for maritime vessel detection and differentiation, which leveraged open source YOLO model architecture.
Post-development, Scale’s model was evaluated using standard machine learning performance metrics including precision, recall, and intersection over union (IOU). This testing helped identify which vessel classes were the most difficult for the CV model to detect, and helped Scale prioritize label generation for the maritime vessels that were the most challenging for the model to identify in the first development cycle.
With a clear understanding of what object classes were high-priority, Scale began a second development cycle. During this time, Scale annotated an additional 44,0000 labels to further improve detection and classification performance, with the bulk of the new data being composed of priority object classes. This data was then added to the initial training data pool and used for model training, resulting in a production-quality model that could accurately detect and differentiate between the different vessel classes seen around the test site.
Scale’s models were benchmarked against a leading open-source model and dataset available for this problem (YOLOv5 trained on the 860,000 annotations included in the Common Objects in Context [COCO] dataset).
Results
Scale’s first model iteration, which was trained on 44,000 labels, outperformed the open-source benchmark model across every metric measured, including precision, recall, accuracy, and IOU, and on every test scenario evaluating efficacy. The performance gains can be easily visualized by comparing the smoothness and vessel fidelity of the baseline model (top image) with Scale’s model (bottom image).


Cycle Two Results
Scale's second model iteration showed additional performance gains across all of the standard CV performance metrics. Detections became even cleaner and more consistent, with fewer misclassifications.


Discussion
Curating and tailoring the training data used for these bespoke models allowed DIU and USAF to boost computer vision performance well beyond the levels achievable with exclusive use of existing data paired with open-source model architectures.
Designing models for highly specialized tasks (like determining the specific types of vessels in frame) can reduce the requisite size of the ontology, resulting in reduced training data quantity requirements. These efficiencies cascade through the development process, reducing overall costs, development time, and testing requirements throughout the entire training, refinement, and deployment process. Even though the datasets used to train the benchmark model and Scale’s model are starkly different in label count and ontology, the marginal cost of developing an additional label for either dataset is the same, so building more focused models with a tailored objective can result in more cost-efficient model development.
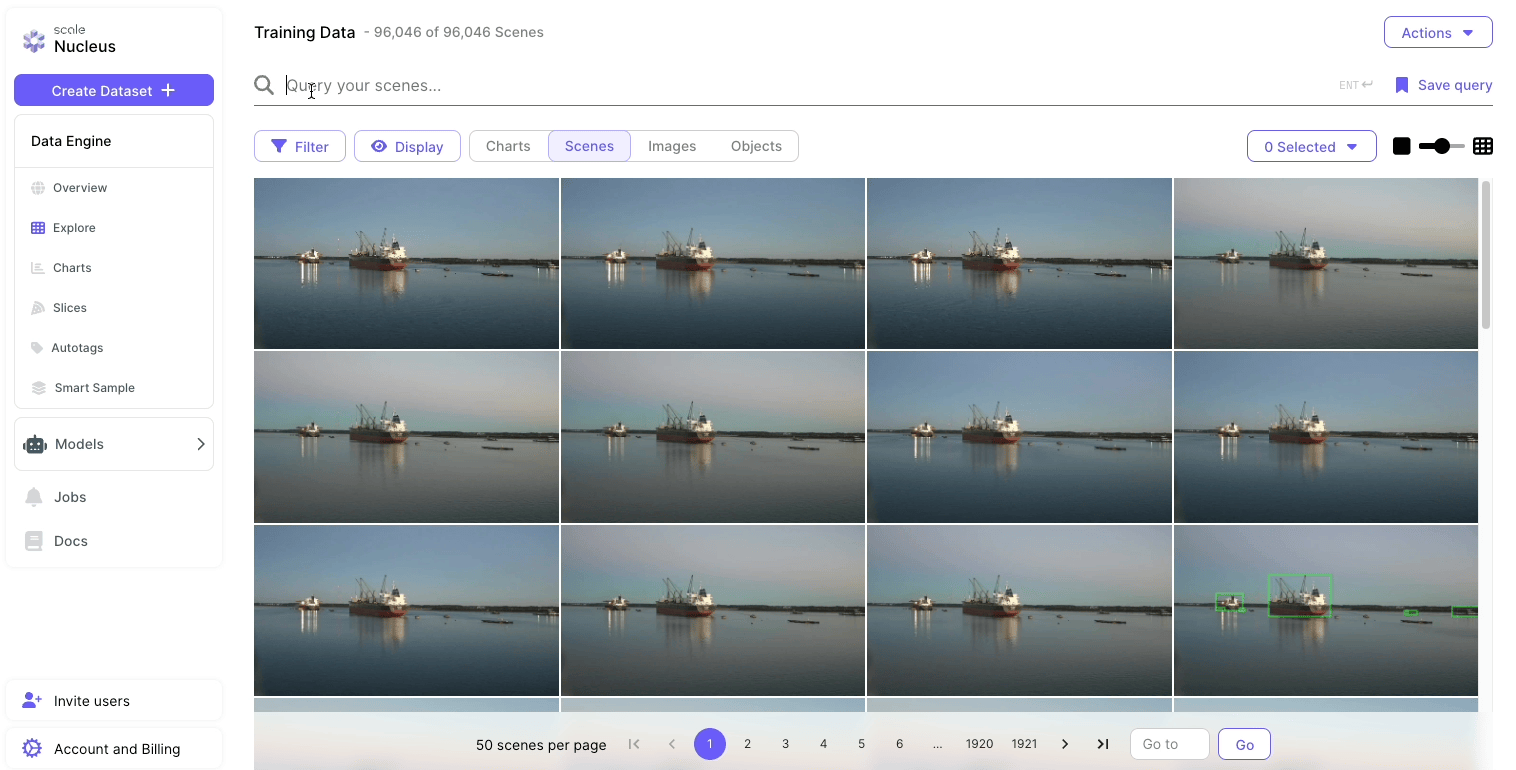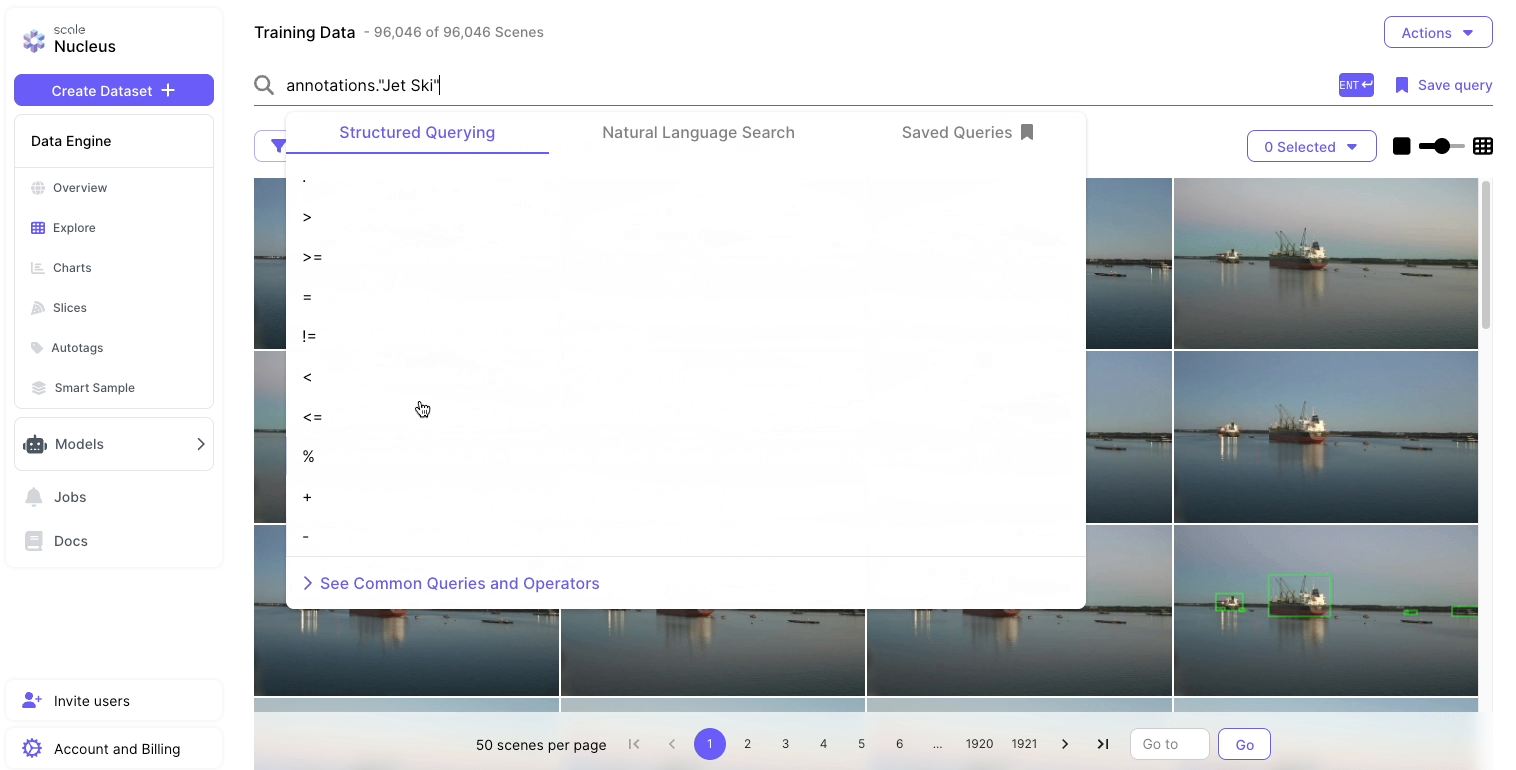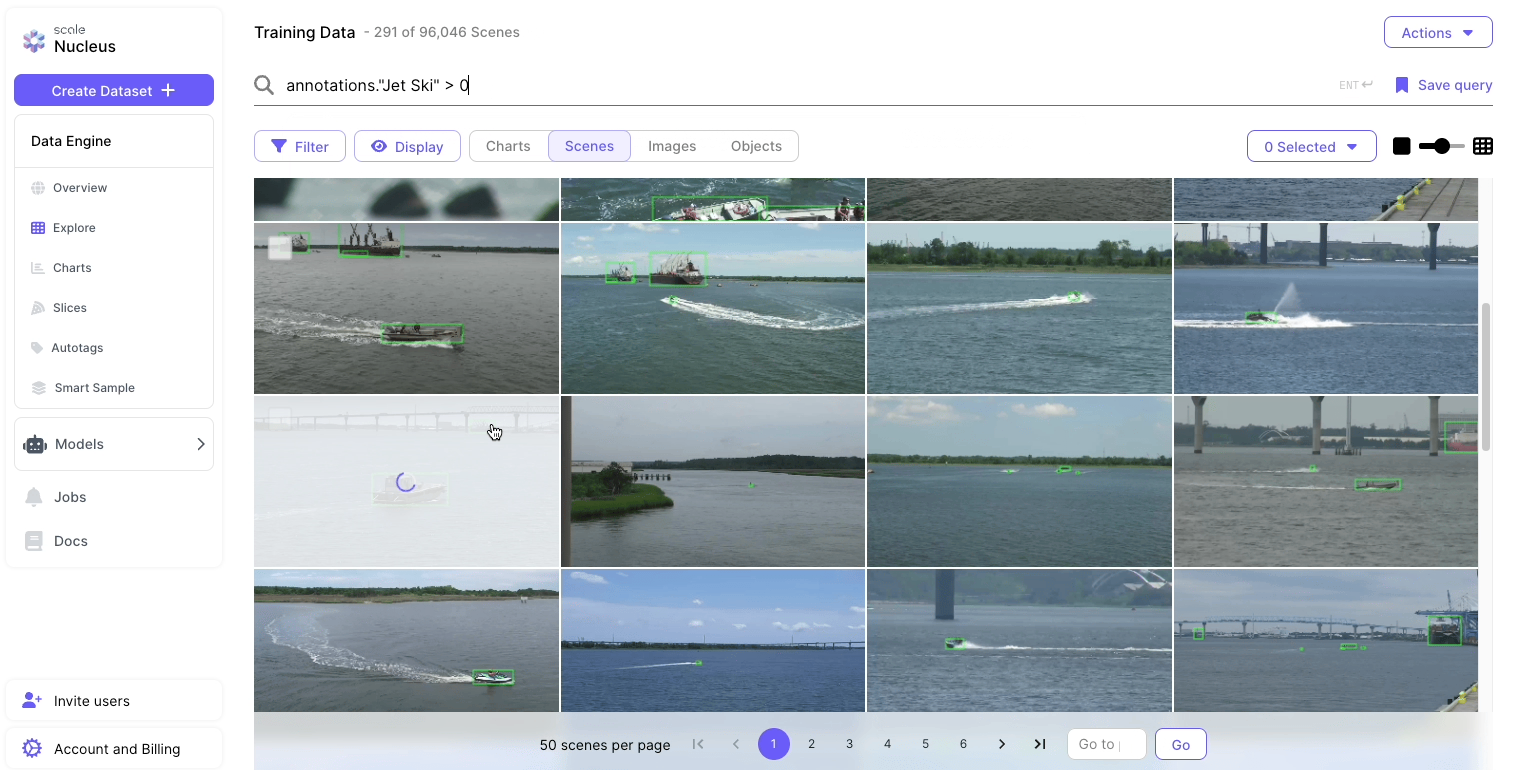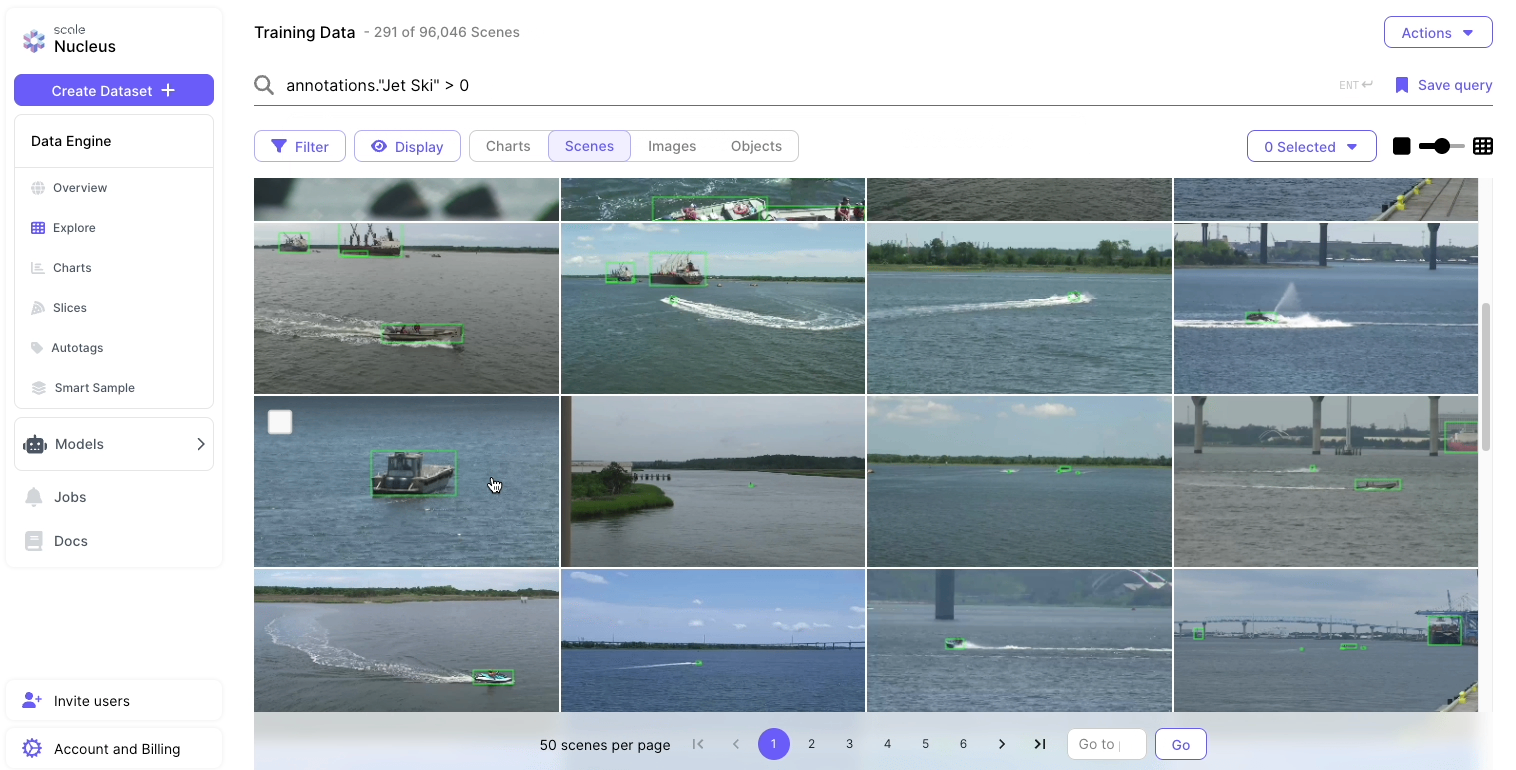
Scale’s Data Engine streamlined each part of the MLOps cycle to develop a computer vision model in a timely and cost-efficient manner.
- Scale’s Data Engine organizes and accesses all of the raw FMV data and completed annotations. These completed annotations are property of the government, and can be reused across other government agencies and industry partners to build similar computer vision programs.
- Within Data Engine, there are various product features designed to expedite the ML Ops process. In particular, similarity search helped us surface rare object classes such as jet skis and data with unusual background noise, raising the performance yields for each following development cycle.
- Testing and evaluation features in Data Engine helped developers understand model performance and performance evaluation to refine Scale’s models. This helped the team identify which vessel classes were the most problematic for the first model and allowed us to prioritize curating particular object classes for labeling for each follow-on development sprint.
- After the first complete MLOps cycle, Scale integrated the first maritime vessel detection model into the pre-labeling tooling available within Scale’s Data Engine. This tooling used the detections generated from the first model to create initial labels for new data added to Data Engine, enabling our expert labeling workforce to spend less time per annotation, driving down development time and associated costs, and allowing for faster model production.
This work demonstrates the flexible and powerful nature of CV, which can be applied to existing problems to create new capabilities without incurring the costs associated with developing entirely new technology. Any object can be detected as long as the right dataset is created and utilized for model training. With a well-defined ontology and use case, computer vision can augment existing workflows and enable military personnel to monitor greater volumes of unmonitored locations with existing personnel. The case highlighted above is just one of many examples of Scale creating new models for specialized use cases with bespoke data. CV could be used in numerous U.S. government mission areas such as:
- The Autonomous Perimeter Security system that DIU prototyped for this project can be deployed anywhere in the world. This system can scale to monitor a larger area of interest by deploying more towers, without requiring more manned bases or outposts. This technology could be used to monitor real-time activity in the South China Sea, with thousands of miles of coastline being covered. As soon as certain vessel classes were detected, alerting would notify U.S. Naval forces to the activity.
- With the right training data, a CV algorithm could be trained to determine how many civilian and uniformed military personnel are entering and exiting a building. A more sophisticated model could classify the national affiliation of each uniformed military person, allowing intelligence analysts to determine which military forces may be collaborating or engaging in diplomatic engagements.
About Scale AI
Scale has established partnerships with customers such as Air Force Research Lab, OpenAI, and the Pentagon’s Chief Digital and Artificial Intelligence Office. Scale is providing robust support for a range of DoD-adjacent customers, delivering proven commercial technology tailored for defense applications. Scale is recognized as a labeling partner for the CDAO and is equipped to label data modalities like 2D imagery, LiDAR point cloud, text, sonar/acoustic data, and more. Our Data Engine can be deployed into FedRAMP or classified government environments.
Learn more here: https://scale.com/public-sector-data-engine
Ready to break through your data bottleneck?
Scale's team will match your project to the right experts, fast.
